---
title: 開啟 TensorFlow 自動混合精度運算與執行效能分析
tags: HowTo, CCS, Interactive, TW
GA: UA-155999456-1
---
{%hackmd @docsharedstyle/default %}
# HowTo: 開啟 TensorFlow 自動混合精度運算與執行效能分析
本文將逐步教學使用者如何運用 TWCC 開發型容器,並以 MNIST 手寫辨識模型程式為例,開啟 TensorFlow 深度學習的自動混合精度 (Automatic Mixed Precision, 以下簡稱 AMP) 運算功能,達到維持模型準確度並縮短運算時間,最後利用 ResNet-50 進行簡易的效能分析,內容大綱如下:
- AMP 簡介
- 建立 TWCC 開發型容器
- SSH 連線進入容器
- 開啟 AMP 功能
- 環境變數設定方式
- MNIST 手寫辨識程式撰寫範例
- Benchmark 效能分析:ResNet-50 v1.5
## AMP 簡介
傳統的高效能計算採用雙精準度 (Double Precision) 運算,能確保數值演算法的收斂特性 (例:大氣模擬)。雙精準度運算 (FP32) 讓每個數值佔據 32 個位元,並可達到 16 個欄位的精準度,而此種計算需要大量記憶體空間。
而有些數值運算 (例:深度學習) 不需要全部仰賴雙精準度運算,採用自動混合精度運算 (AMP) 可加速運算速度,並維持模型準確度。
:::info
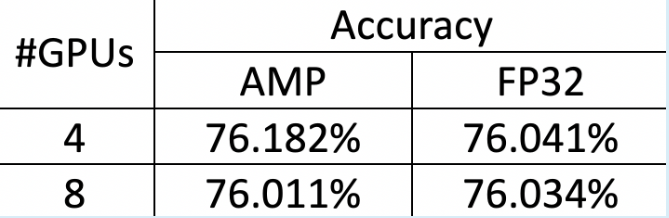
:bulb: 經以下測試,模型準確度確實不受 AMP 影響:
- 利用 ResNet-50 v1.5 模型進行 ImageNet 資料集 (140 GB) 圖形識別模型訓練
- 使用 4 或 8 個 GPU,經過 50 個 epochs 訓練後,準確度 (Accuracy) 如下,雙精準度運算 (FP32)和自動混合精度運算 (AMP) 呈現出相近的準確度:
:::
以下教學如何開啟 TWCC 開發型容器的 AMP 功能。
## 建立 TWCC 開發型容器
登入 TWCC 後,請參考 [建立開發型容器](https://www.twcc.ai/doc?page=container#%E5%BB%BA%E7%AB%8B%E9%96%8B%E7%99%BC%E5%9E%8B%E5%AE%B9%E5%99%A8),建立一個如以下設定的容器:
```
映像檔類型:TensorFlow
映像檔版本:tensorflow-19.08-py3:latest
基本設定: c.super
```
## SSH 連線進入容器
於「開發型容器管理」頁面待開發型容器的狀態轉為「Ready」時,點選該容器進入「開發型容器詳細資料」頁面。可透過 Jupyter Notebook 或 SSH 連線使用容器。本教學內容採用 SSH 連線,詳細步驟請參閱 [使用 SSH 登入連線](https://www.twcc.ai/doc?page=container#%E4%BD%BF%E7%94%A8-SSH-%E7%99%BB%E5%85%A5%E9%80%A3%E7%B7%9A)。
## 開啟 AMP 功能
開啟 AMP 功能包含兩步驟:設定環境變數與改寫運算程式,示範如下:
### 環境變數設定方式
Bash shell 環境變數設定方式,可直接於命令列輸入指令如下:
```bash=
$ export TF_ENABLE_AUTO_MIXED_PRECISION=1
$ export TF_ENABLE_AUTO_MIXED_PRECISION_GRAPH_REWRITE=1
```
:::info
:bulb: TWCC 開發型容器 (TensorFlow 19.08-p3:latest) 已預設啟用自動混合精度運算,可使用 ```echo $TF_ENABLE_AUTO_MIXED_PRECISION``` 指令驗證:<br>
回應 = 1 表示**已啟用**自動混合精度運算
回應 = 0 表示**已停止**自動混合精度運算
:::
### 程式撰寫範例
- Graph-based example:
```python=
opt = tf.train.AdamOptimizer()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
train_op = opt.miminize(loss)
```
- Keras-based example:
```python=
opt = tf.keras.optimizers.Adam()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
model.compile(loss=loss, optimizer=opt)
model.fit(...)
```
### MNIST 手寫辨識程式撰寫範例
利用 Keras 搭配 TensorFlow 進行 MNIST 資料集數字手寫辨識的 Python 程式開啟 AMP 的方式如下:
```python=
import tensorflow as tf
start_time = time.time()
opt=keras.optimizers.Adadelta()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=opt,
metrics=['accuracy'])
elapsed_time = time.time() - start_time
print('Time for model.compile:', elapsed_time)
```
:::info
:bulb: `KerasMNIST.py` (未開 AMP) & `kerasMNIST-AMP.py` (開啟AMP) 程式檔案可於[此處](https://github.com/TW-NCHC/AI-Services/tree/master/Tutorial_One)下載參考
:::
## Benchmark 效能分析:ResNet-50 v1.5
以下根據五組不同的設定,分別訓練 ResNet-50 v1.5 圖片辨識模型,並比較運算效能:
| 組別| AMP | XLA | 精準度 Precesion |Batch Size |
| -------- | -------- | -------- | -------- | -------- |
| 1| :negative_squared_cross_mark: | :negative_squared_cross_mark: | 雙精準度 | 128 (Baseline) |
| 2| :negative_squared_cross_mark: |:negative_squared_cross_mark: | 雙精準度 | 256 |
| 3| :white_check_mark: | :negative_squared_cross_mark: | 單、半精準度混合 | 256 |
| 4| :white_check_mark: | :white_check_mark: | 單、半精準度混合 | 256 |
| 5| :white_check_mark: | :white_check_mark: | 單、半精準度混合 | 512 |
:::info
註:Accelerated Linear Algebra (XLA) 能優化 TensorFlow 運算,加速執行速度。
:::
建立 TWCC 開發型容器 (TensorFlow 19.08-p3:latest) 後,ResNet-50 v1.5 範例程式已存在於 `/workspace/nvidia-examples/resnet50v1.5` 目錄內,在此目錄下創建新的目錄 (例:results) 用來存放模型資料。在命令列輸入指令如下:
```bash=
$ cd /workspace/nvidia-examples/resnet50v1.5
$ mkdir results
```
### Group 1. 對照組 Baseline
> 未開 AMP | 雙精準度|Batch size = 128
因環境預設開啟自動混合精度運算,所以執行對照組需先將環境變數強制停止自動混合精度運算,直接於命令列輸入執行指令如下:
```bash=
$ export TF_ENABLE_AUTO_MIXED_PRECISION=0
$ export TF_ENABLE_AUTO_MIXED_PRECISION_GRAPH_REWRITE=0
$ python ./main.py --mode=training_benchmark --warmup_steps 200 \
--num_iter 500 --batch_size 128 --iter_unit batch --results_dir results \
--nouse_tf_amp --nouse_xla
```
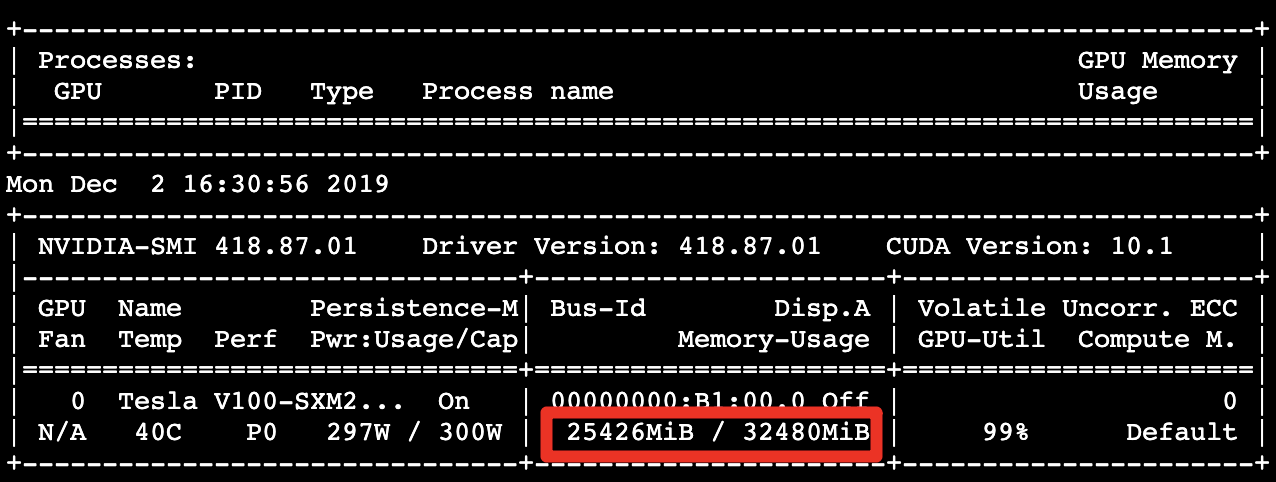
使用以下指令每間隔 10 秒動態觀察 GPU 記憶體的使用量,即時觀察 GPU 記憶體的使用量約 25.43 GB 尚未用滿 GPU 記憶體配置容量 (32.48 GB):
```bash=
$ nvidia-smi --loop=10
```
模型訓練完成,每秒能處理約 393.49 個影像:

### Group 2. Batch Size 256
> 未開 AMP | 雙精準度 | Batch size = 256
從對照組動態觀察 GPU 記憶體的使用量,發現 GPU 記憶體尚未被用滿,所以將 Batch Size 加倍,直接於命令列輸入執行指令如下:
```bash=
$ rm -rf results/*
$ python ./main.py --mode=training_benchmark --warmup_steps 200 \
--num_iter 500 --batch_size 256 --iter_unit batch --results_dir results \
--nouse_tf_amp --nouse_xla
```
GPU 記憶體的使用量 31.31 GB:
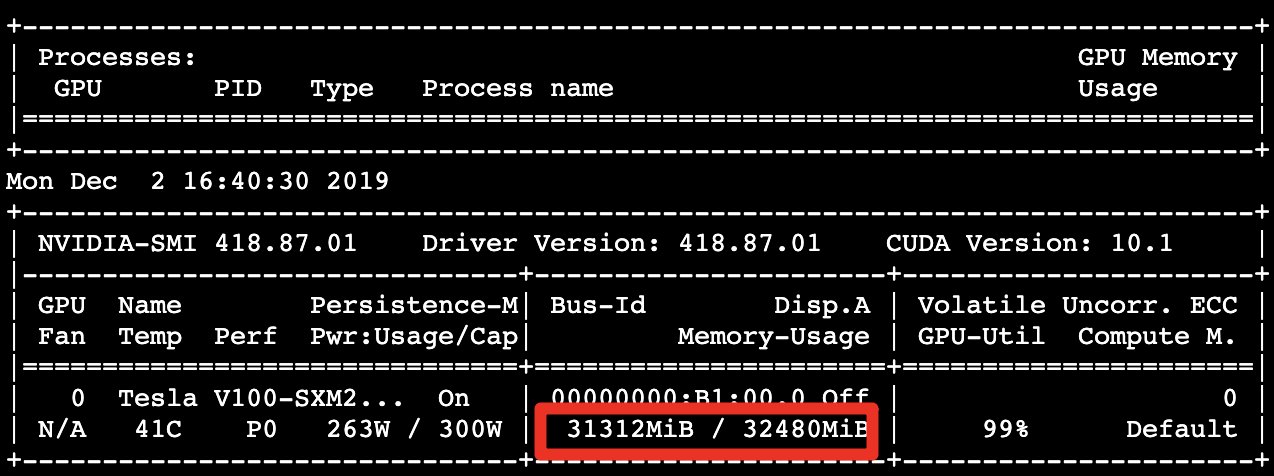
每秒處理約 405.73 個影像,呈現出優於對照組 1.03 倍的效能:

### Group 3. 開啟 AMP
> 開啟 AMP | 單、半精準度混合|Batch size = 256
輸入以下指令將環境變數設定開啟 AMP,並執行運算:
```bash=
$ rm -rf results/*
$ export TF_ENABLE_AUTO_MIXED_PRECISION=1
$ export TF_ENABLE_AUTO_MIXED_PRECISION_GRAPH_REWRITE=1
$ python ./main.py --mode=training_benchmark --warmup_steps 200 \
--num_iter 500 --batch_size 256 --iter_unit batch --results_dir results \
--nouse_xla
```
GPU 記憶體的使用量大幅降低至 19.28 GB:
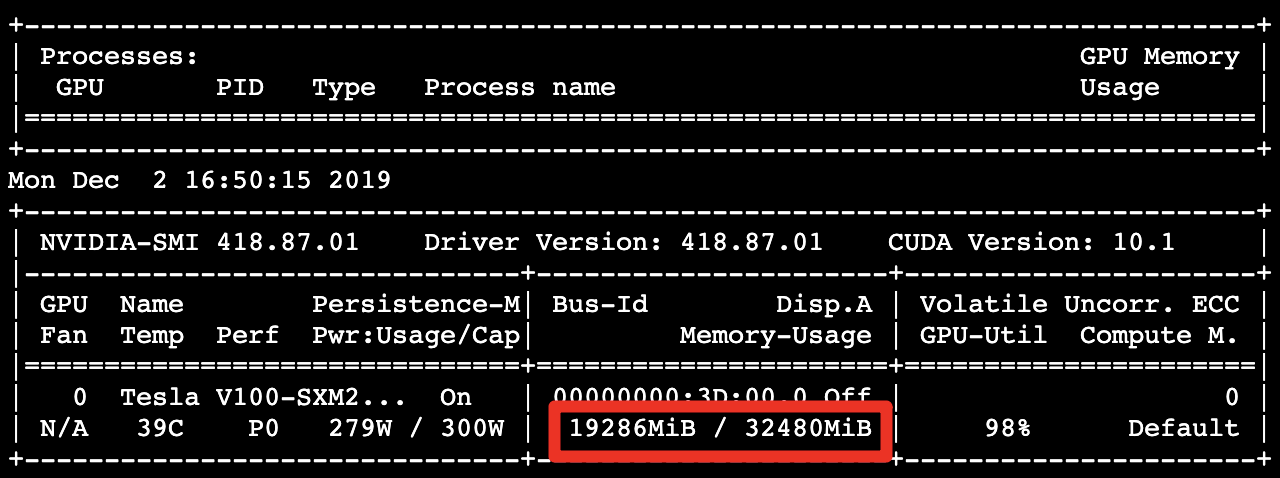
每秒處理約 1308.37 個影像,呈現出優於對照組 3.33 倍效能:

### Group 4. 開啟 XLA
> 開啟 AMP、XLA | 單、半精準度混合|Batch size = 256
直接於命令列輸入指令如下:
```bash=
$ rm -rf results/*
$ python ./main.py --mode=training_benchmark --warmup_steps 200 \
--num_iter 500 --batch_size 256 --iter_unit batch --results_dir results
```
GPU 記憶體的使用量 19.29 GB:
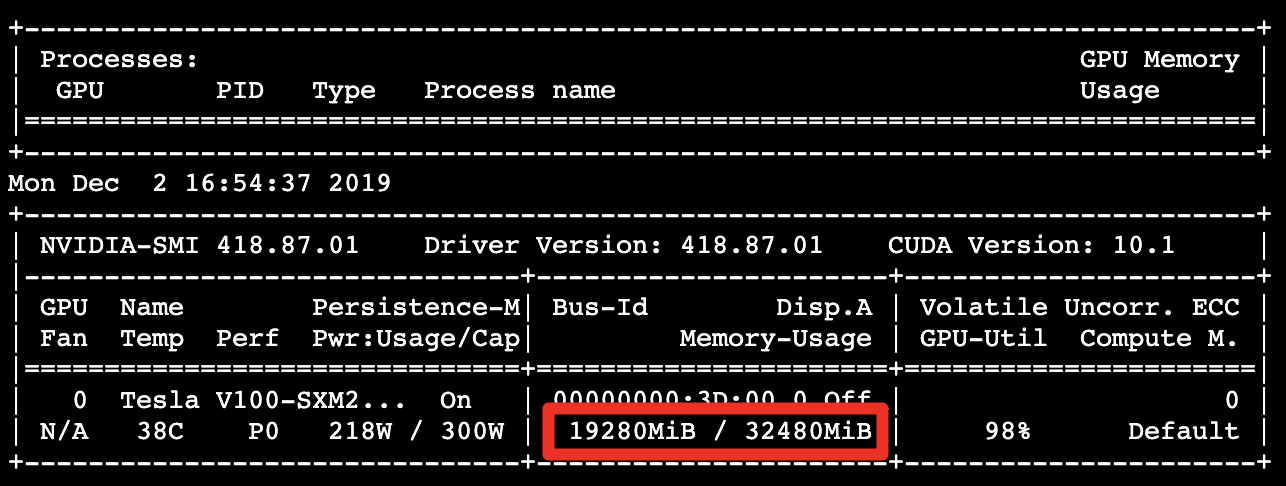
每秒處理約 1309.21 個影像,呈現出優於對照組 3.33 倍效能:

### Group 5. 再加倍 Batch Size
> 開啟 AMP、XLA | 單、半精準度混合 |Batch size = 512
:::spoiler ResNet-50 v1.5 Benchmark 效能分析 運行範例
::: info
你可直接透過下列指令進行 ResNet-50 的運行效能分析,運行時間約 3分鐘
`wget -q -O - http://bit.ly/TWCC_CCS_AMP-XLA | bash`
:::
因為 AMP 大大地降低 GPU 記憶體的使用量,所以我們再加倍 Batch Size 企圖增加執行效能,直接於命令列輸入指令如下:
```bash=
$ rm -rf results/*
$ python ./main.py --mode=training_benchmark --warmup_steps 200 \
--num_iter 500 --batch_size 512 --iter_unit batch --results_dir results
```
GPU 記憶體的使用量 31.31 GB:
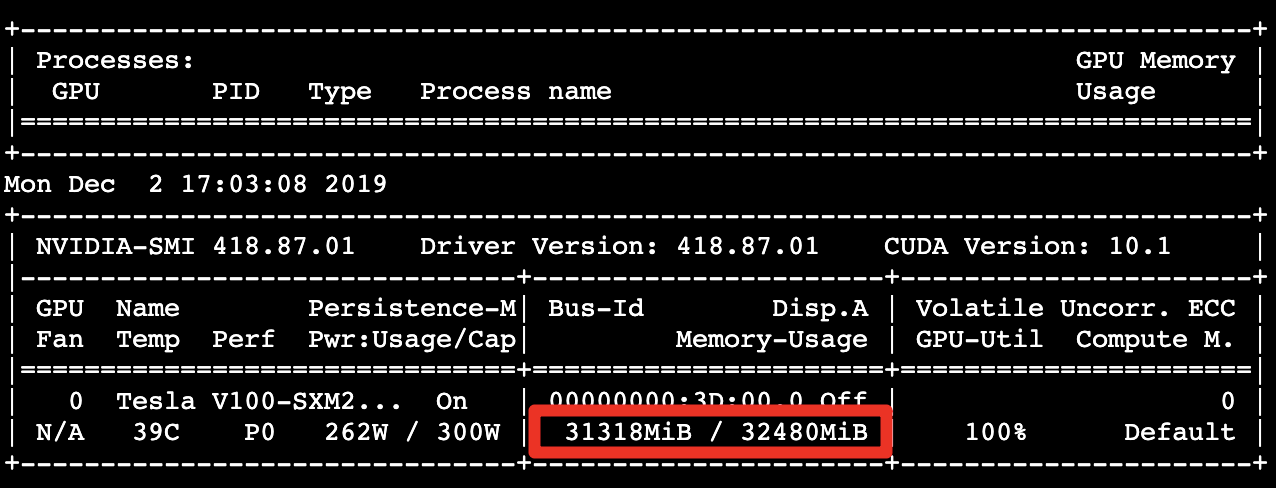
每秒處理約 1361.00 個影像,呈現出優於對照組 3.46 倍效能:

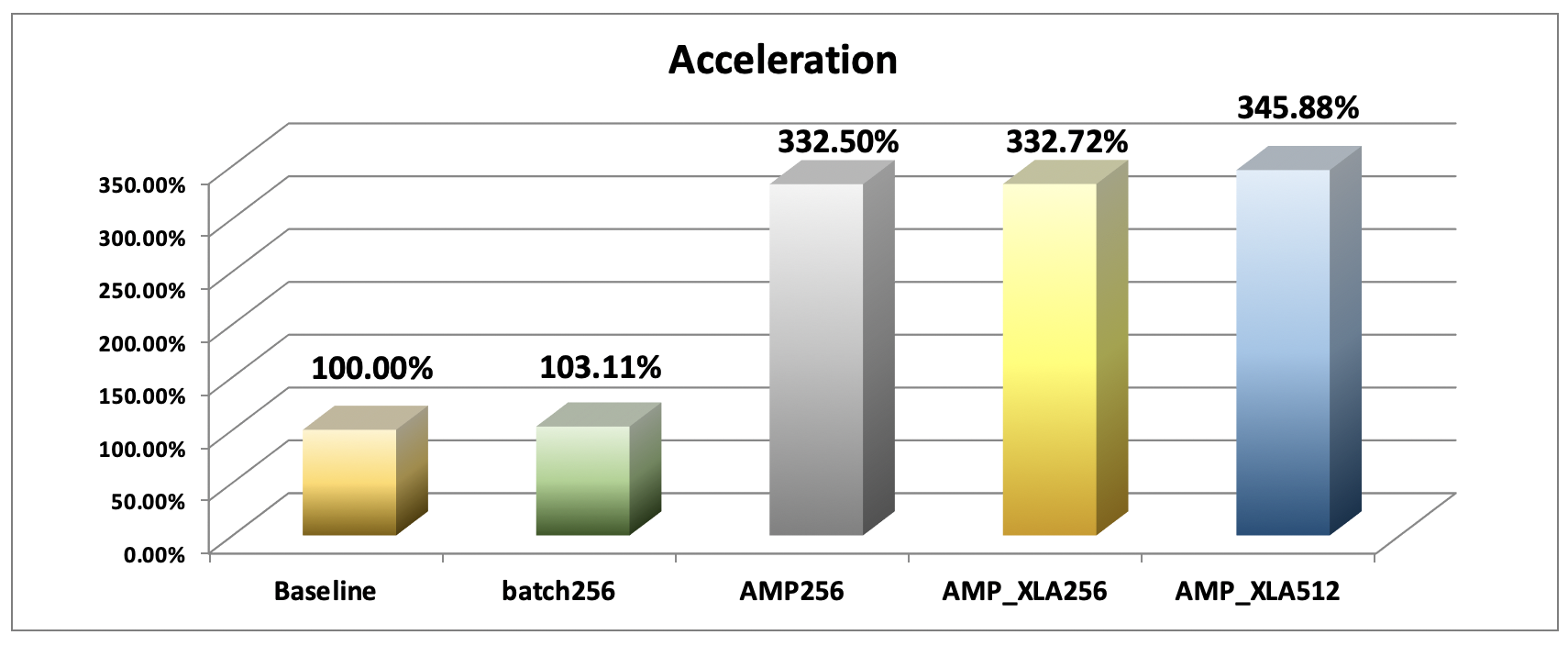
### 效能比較
彙整以上每組影像處理數據結果 (img/sec、GPU 記憶體使用量),效能比較呈現如下圖表,與對照組相比,開啟 AMP 加速運算的效能相當顯著,降低 GPU 記憶體使用量並縮短訓練運算時間:
| 組別| AMP | XLA | 精準度 Precesion |Batch Size |每秒處理影像數 (img/sec) | GPU 記憶體使用量 (GB)|
| -------- | -------- | -------- | -------- | -------- |-------- |-------- |
| 1 (Baseline)| :negative_squared_cross_mark: | :negative_squared_cross_mark: | 雙精準度 | 128 |393.49 |25.43|
| 2| :negative_squared_cross_mark: |:negative_squared_cross_mark: | 雙精準度 | 256 |405.73|31.31|
| 3| :white_check_mark: | :negative_squared_cross_mark: | 單、半精準度混合 | 256 |1308.37|19.29|
| 4| :white_check_mark: | :white_check_mark: | 單、半精準度混合 | 256 |1309.21|19.29|
| 5| :white_check_mark: | :white_check_mark: | 單、半精準度混合 | 512 |1361.00|31.31|