---
title: GPU 資源調度 | zh
tags: Guide, TWNIA2, TW
GA: UA-155999456-1
---
{%hackmd @docsharedstyle/default %}
{%hackmd @docsharedstyle/twccheader-zh %}
# GPU 資源調度
前面介紹過如何為任務指定資源參數,但只包含了節點數量、CPU使用量,以及記憶體使用量等。但專業的資源調度系統應該支援多種複雜的硬體資源管理,例如本服務的GPU資源。Slurm透過一種套件實現了通用資源的管理,讓管理者甚至可以開發專用的通用管理套件來做使用,本服務也使用這種套件來進行GPU的資源控管。
Slurm中通用資源被稱之為GRES(Generic Resource),預設情況下Slurm沒有開啟該功能,但本服務為了管理GPU資源,將此功能開啟,並且將管理GPU資源的相關設定套用到每一台Slurm的管理節點以及運算節點上,以實現GPU的資源控管。使用者可以透過「--gres」參數來申請資源,這邊透過一個腳本範例來看如何使用GPU資源。
<div style="background-color:black;color:white;padding:20px;">
#!/bin/bash
date
nvidia-smi
hostname
echo "done"
</div>
當中「date」為顯示當下時間,而「nvidia-smi」顯示GPU的資訊,如果所被分配的資源中有GPU,透過該指令即可看到該GPU的相關資訊以及使用狀況。腳本最後顯示運行的機器名稱,以及列印出「done」字樣。
我們可以透過以下指令來派送任務,並指定所使用的GPU資源數,當中「--gres」為申請通用資源的參數,「gpu」則是本系統所設定的特定通用資源名稱,由於我們開放申請GPU資源,因此參數直接設定為gpu。最後可在gpu後加上冒號,指定資源的使用量,指令範例以及輸出範例如下。
<div style="background-color:black;color:white;padding:20px;">
$ srun --gres=gpu:2 test.sh
</div>
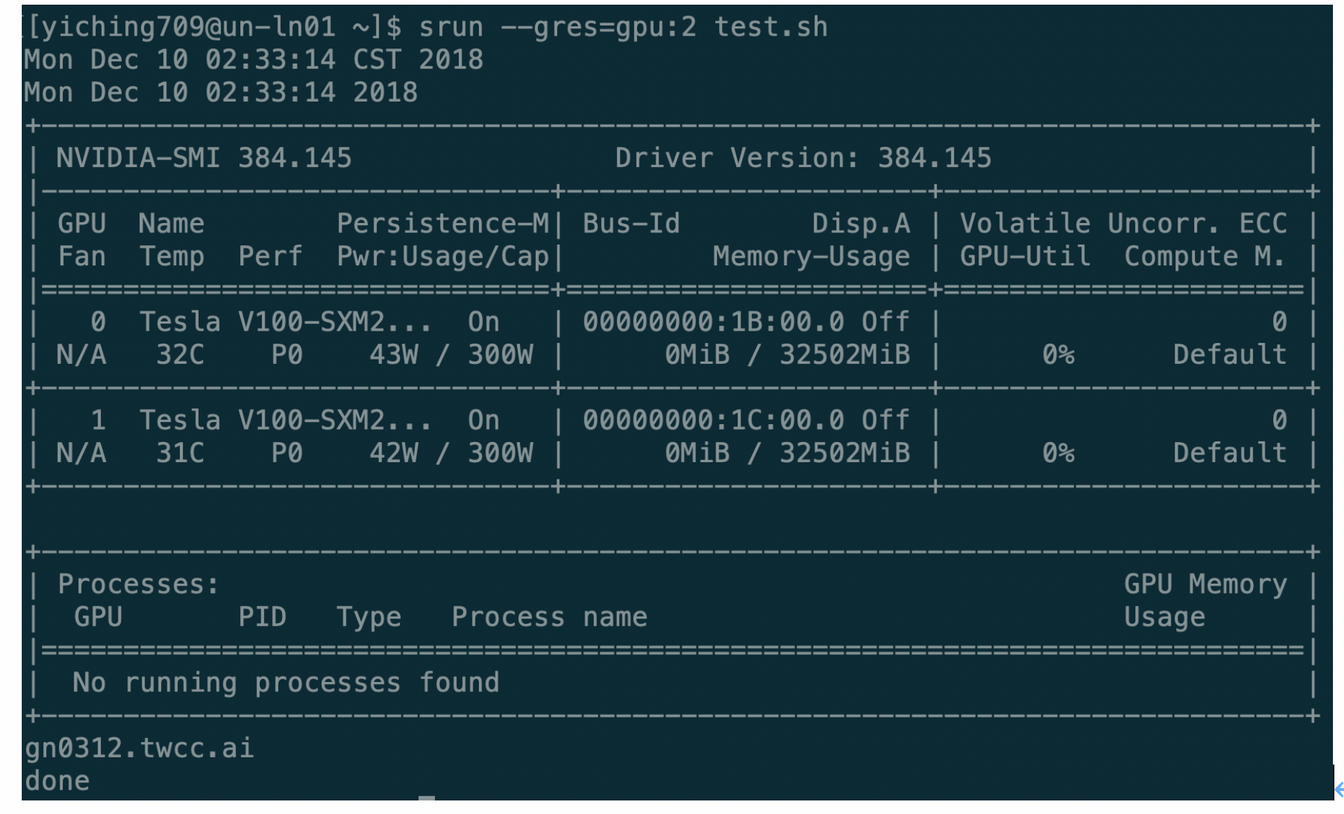
由於我們只有指定兩個GPU資源,因此上圖範例只顯示了兩個GPU卡的資訊,在本系統均使用 Tesla V100的GPU卡。而此範例沒運行需花費GPU資源的程式,因此沒有任何GPU相關處理程序進行。