---
title: Ch2-section4
tags: DAS
GA: UA-155999456-1
---
{%hackmd @docsharedstyle/default %}
# 2.4 Streams flow
:::danger
<i class="fa fa-exclamation-triangle fa-20" aria-hidden="true"></i> **重要:** 目前這個功能需要另外申請使用,請使用者將 TWCC 帳號寫信通知給國網中心DAS管理者<<das@narlabs.org.tw>>,註明[**申請使用 DAS streams flow 功能開通**],並說明使用需求,確認需求與人工驗證完成後,會另外發信通知就可以開通使用。
:::
DAS Streaming Analytics 可以協助用戶取得最新、最即時的資料,並幫忙用戶快速完成即時分析與處理複雜事件的最佳工具。由源源不絕的大資料行成資料流,例如橋樑振動的即時預測、社交媒體資料應用等,由資料的產生即時觸發資料流的工作,將資料清理、彙整、儲存,並提供預測分析一氣呵成。DAS Streams Analytics 提供友善與直覺的開發工具,透過這些互動的開發介面將各種資料來源進行分析,建立資料分析管線,將複雜的即時資料任務變得簡單。
社群與開發團隊也準備了一堆資料讓大家玩!可以瀏覽 [StreamsDev](https://developer.ibm.com/streamsdev/docs/introductory-lab-for-ibm-streams-4-1/) 網站。
如果想體驗 streams 國網中心已經準備好環境,包含有 DAS、Streams、Streams-flow 可以快速導入即時資料串流分析的任務。
以下會依續介紹幾個主題:
* 啟動 streams flow
* 執行 streams flow 任務
* 檢視 streamsflow 狀態與結果
* 修改與設計 streams flow
* 修改 filter
* 使用 aggration
* 使用 code
* Notebook 使用 streams?
## 2.4.1 啟動與檢視 streams flow
使用者登入 TWCC 之後,點選分析大師 (DAS) 即可開始體驗。
起始專案,並增加 streams-flow asset
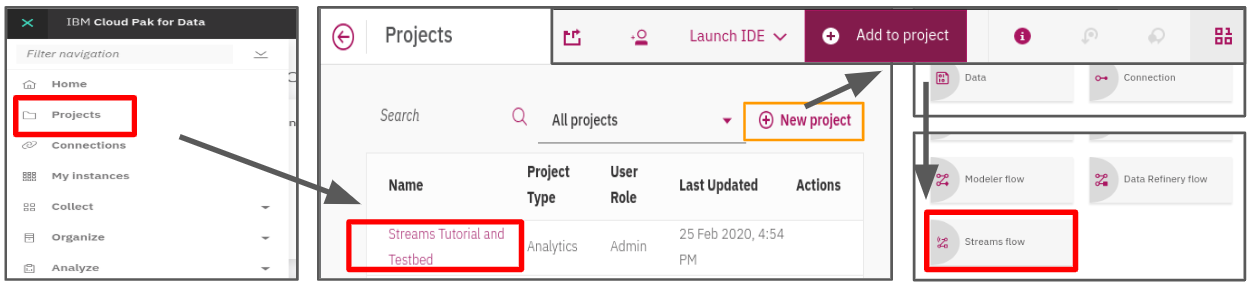
New Streams Flow
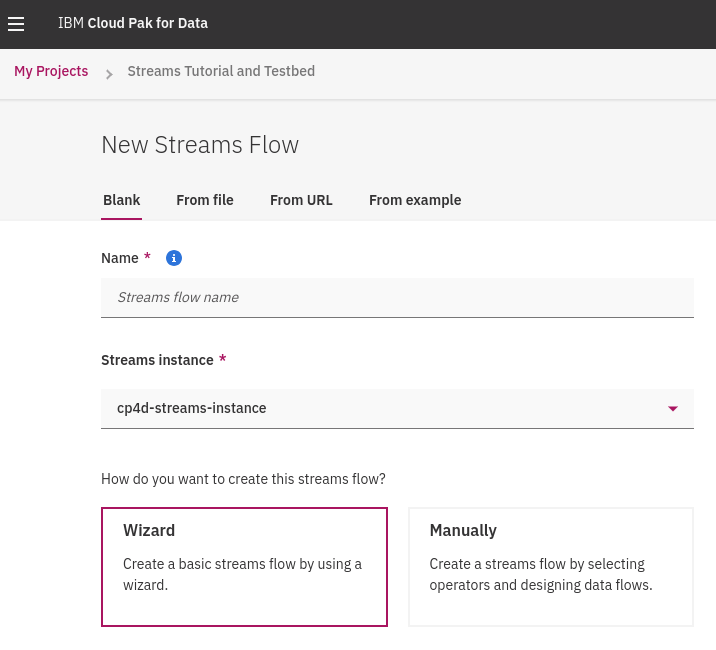
新增 streams flow 設計時,可以由檔案、遠端網址、預設範例、空白專案等開始。
如果選擇由空白專案開始設計 streams 功能,可以選擇由精靈互動式引導,或是僅建立空白專案。
本次教學選擇 已經設計好的範例進行,請點選 **From Example**
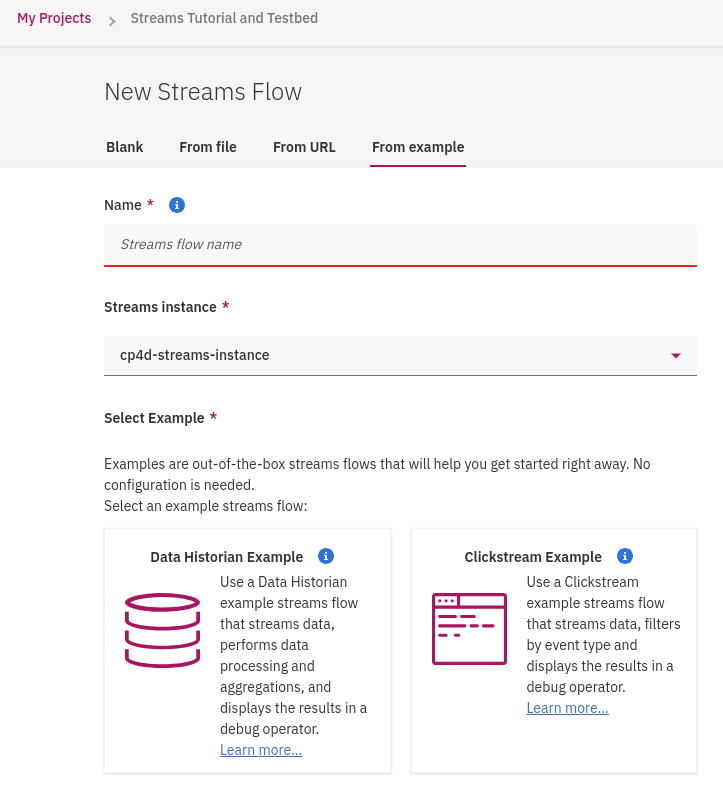
由 DAS Streams 範例教我們如何設計 streams flow 可以發揮最佳學習效果。"Data Historian Example" 範例提供許多感測與時序資料,包含有"station ID, time zone, date in Universal Coordinated Time (UTC) format, latitude, longitude, temperature, barometric pressure, humidity, indoor temperature, 與 rainfall等。
"Clickstream Example" 是一個購物網站範例,包含資料有customer ID, time stamp, type of click event, name of the product, category of the product, price, total price of all products in the basket, total number of all products in the basket, number of distinct items in the basket, 和 how long the user was on the site等。資料由使用者行為整理成 **streams event** 源源不斷的送資料進來,我們可以整理使用者點擊的行為即時做出分析。輸入**Name**,點選 **Clickstream Example** 再點選 **Create** 開始瀏覽範例設計。
<!-- #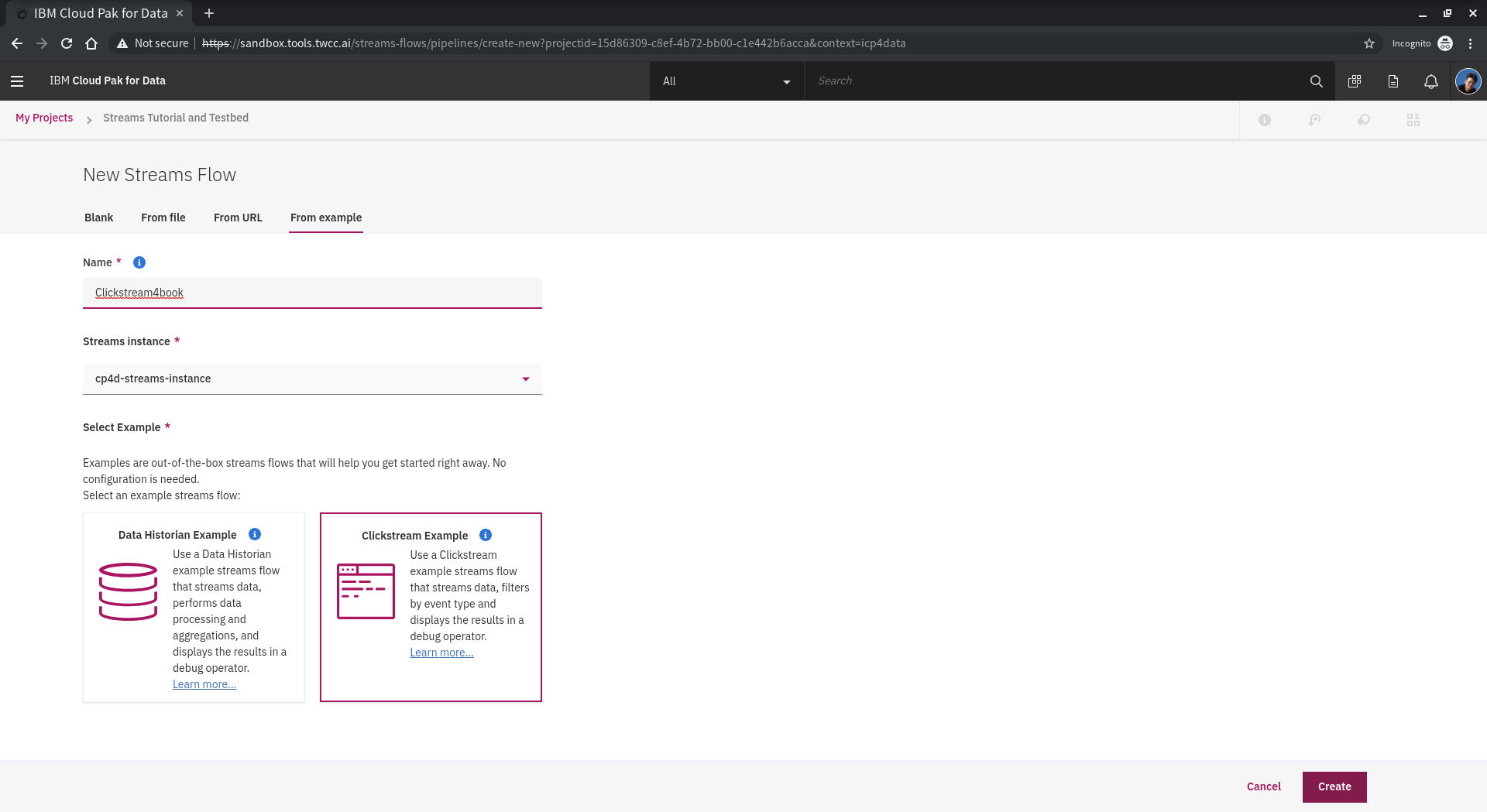 -->
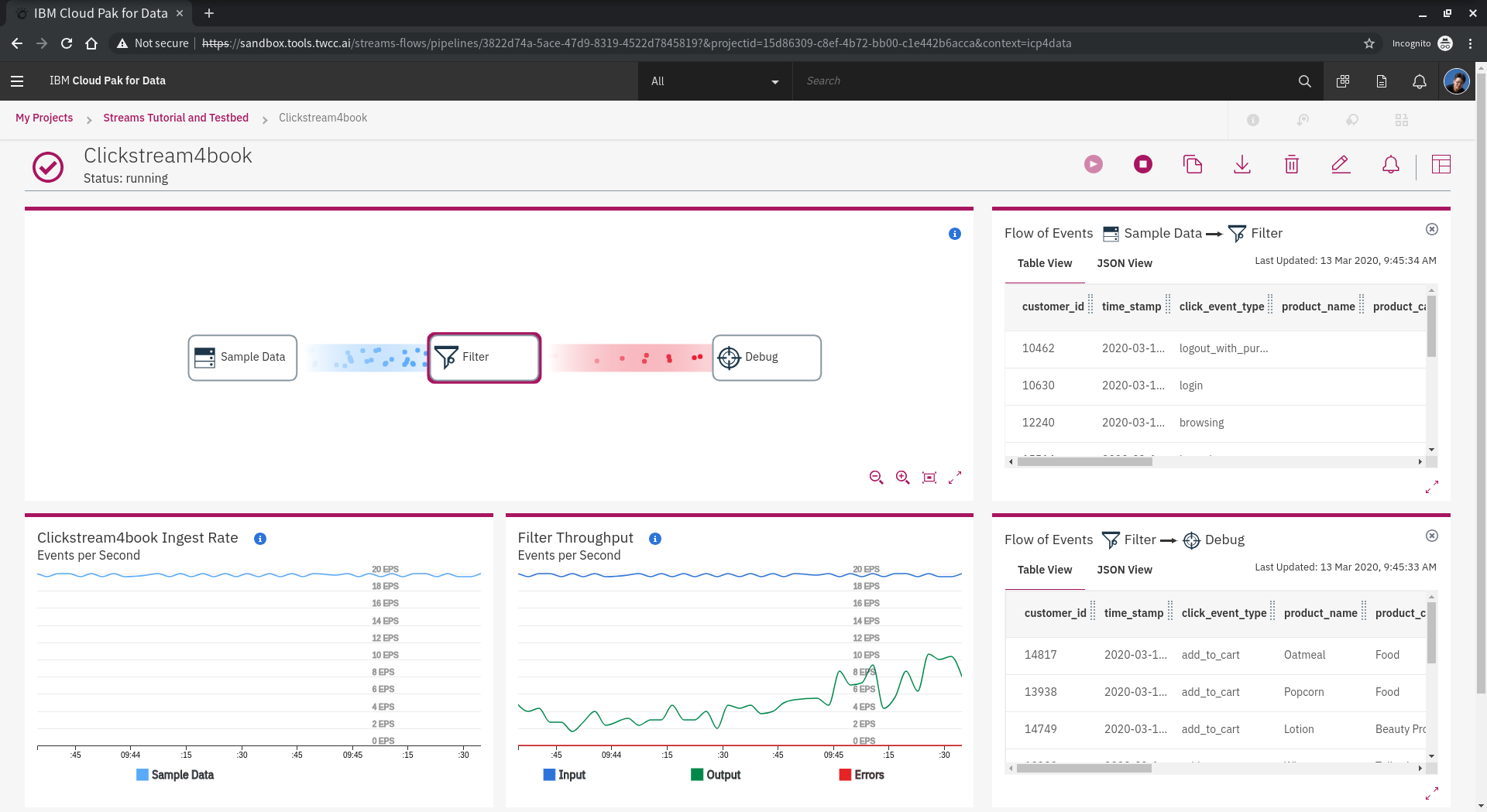
Streams Flow 預覽畫面可以看到 **Sample Data**會產生資料當作 **output** 並提供給 **Filter** 進行資料即時過濾,進行資料清洗,最後把清洗好的資料 **output** 到 **Debug** Console 可以瀏覽資料結果。做而言不如**run**看看!
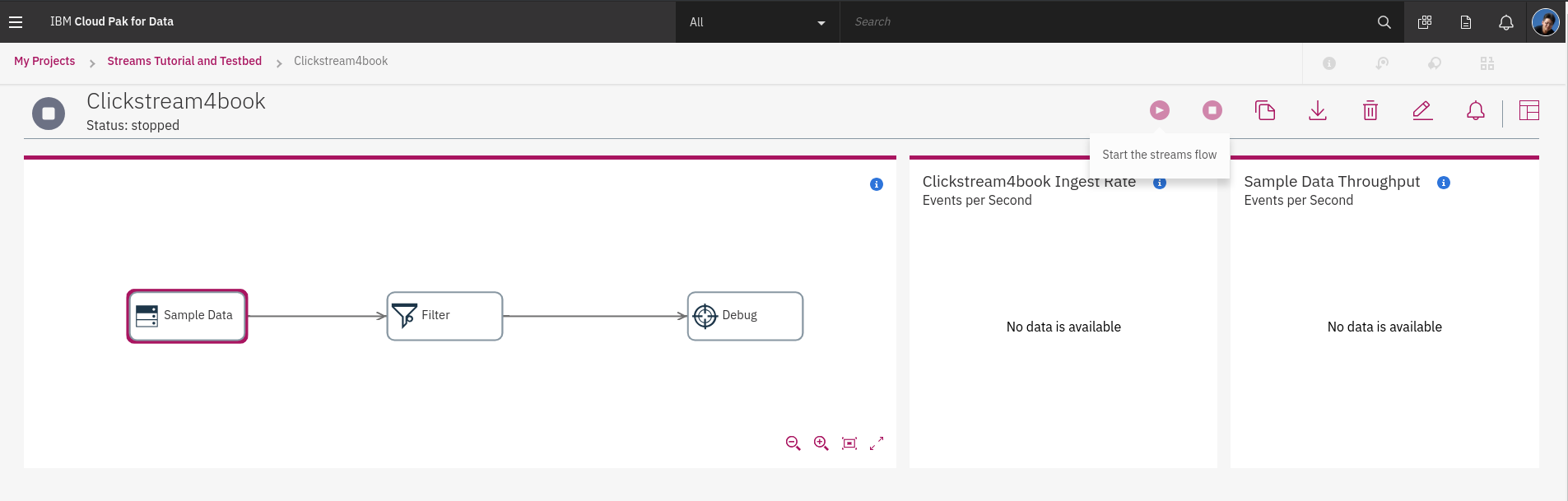
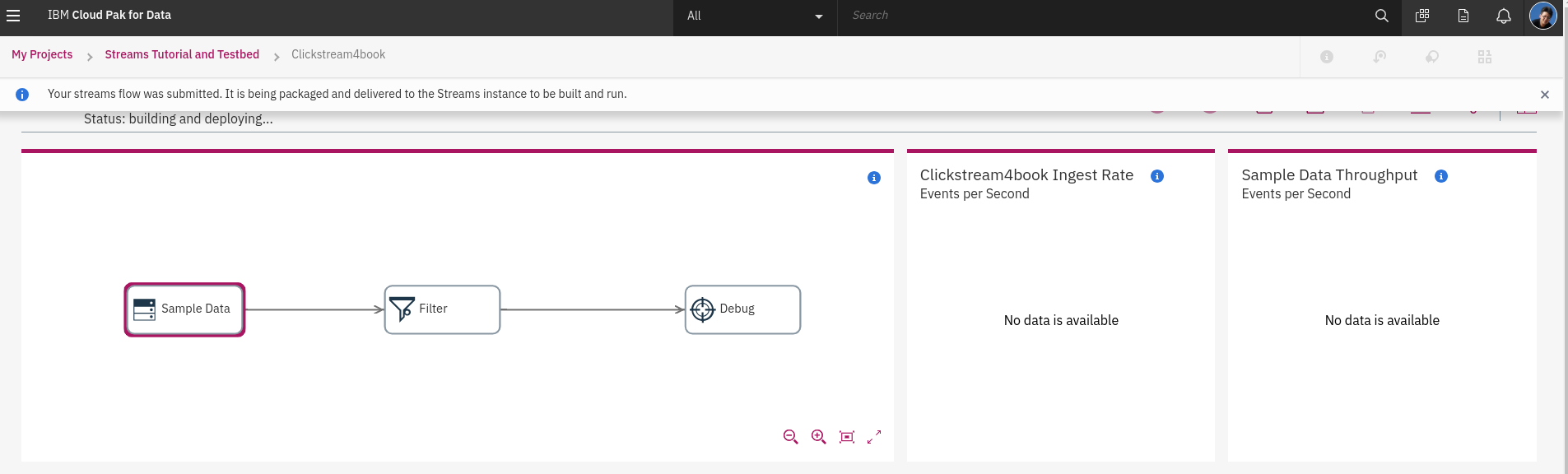
Streams Flow 執行時,會將**畫簿**設計好的流程編譯成程式,將程式轉換為 streans job 並且由 streams instance 執行,DAS 裏面已經啟動了 **"streams4das"** Instance,可以接收使用者設計的流程並佈署與執行任務。
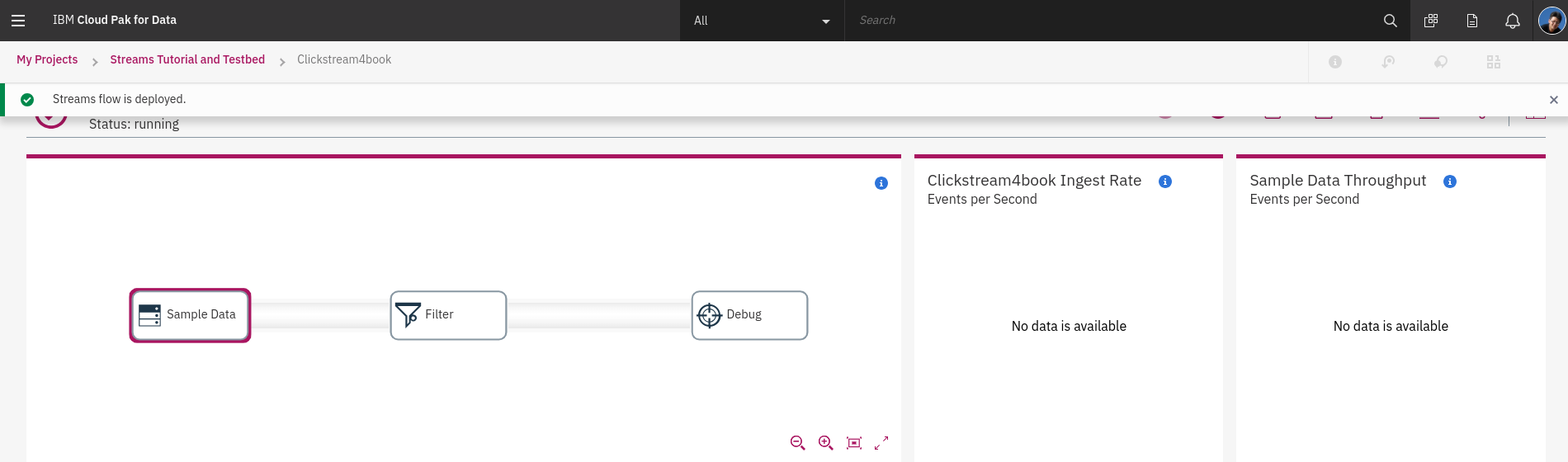
streams 任務開始之後,可以看到狀態顯示為 **running**,不久之後會看到管到之間有源源不絕的 **event** 出現,經過 **Filter**、**Debug**。
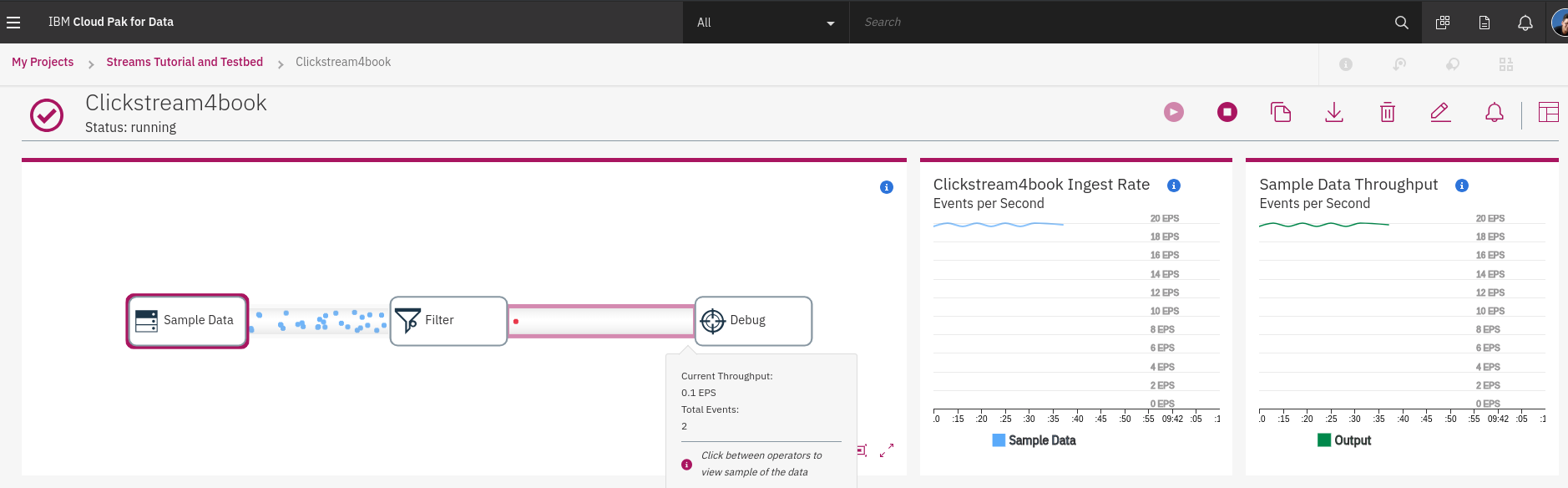
點擊 **Sample Data** 可以看到右邊顯示的資料狀態,左邊flow起始為 Sample Data 的 範例資料流量,單位為 **EPS (Event per Secone)**,右邊為輸出流量統計。

點擊 **Filter** 可以看到右邊顯示的資料狀態,左邊為 Sample Data 的 範例資料流量,右邊為輸出流量統計。滑鼠移到 **Filter Throughput** 可以看到 **Filter** 的 Input. Output 與 Errors 的數量,單位一樣是 EPS。
<!--  -->
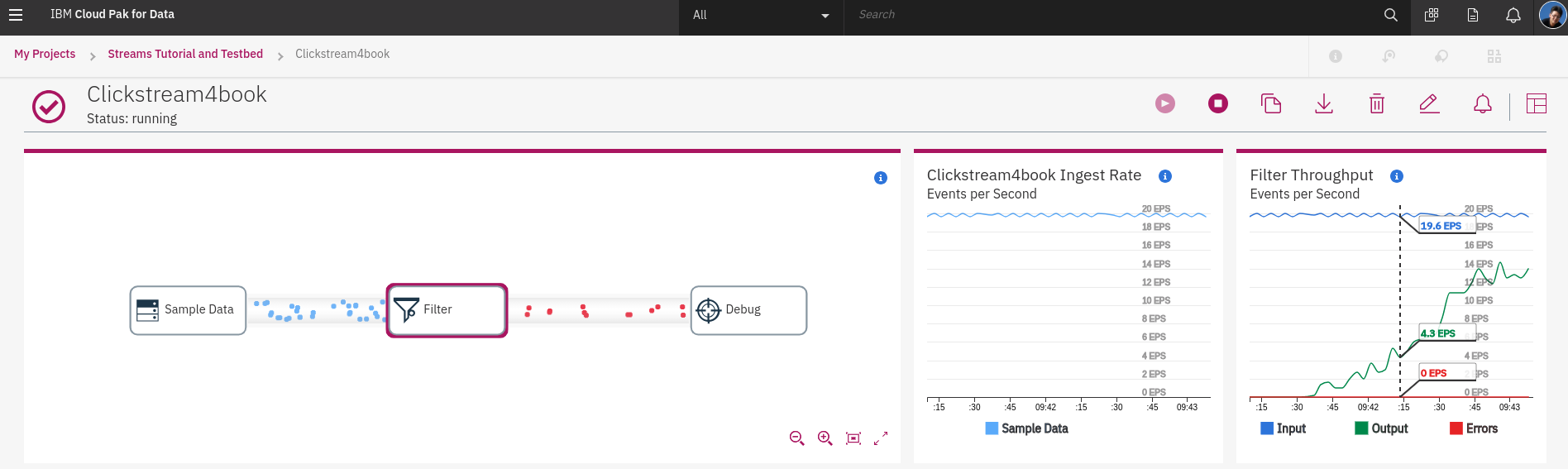
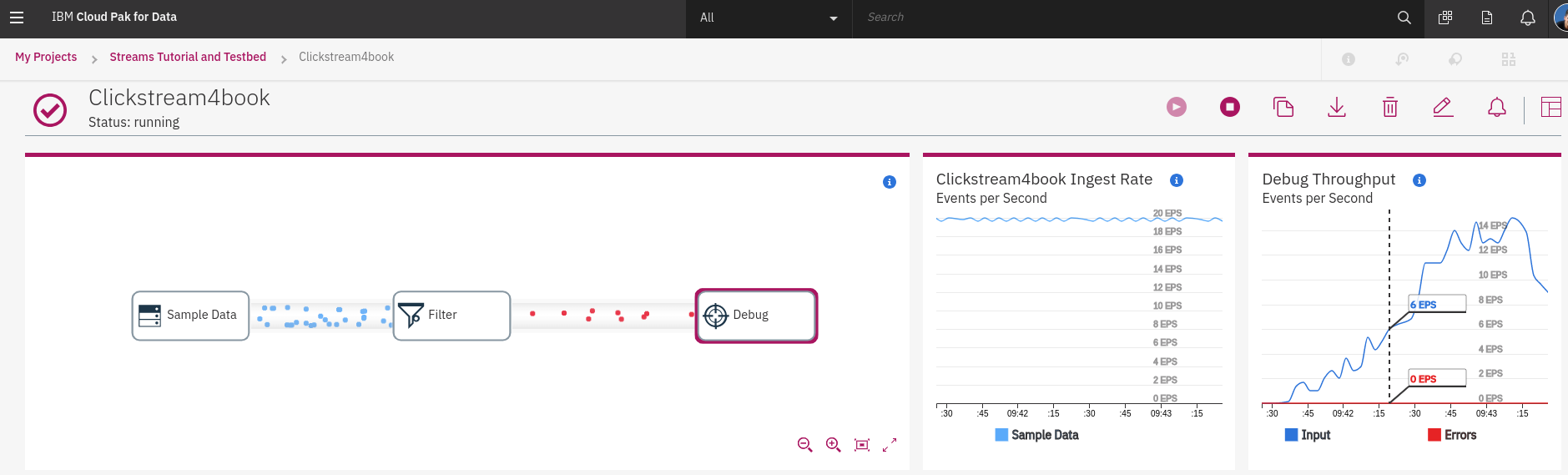
點擊 **Debug** 可以看到右邊顯示的資料狀態,左邊為 Sample Data 的 範例資料流量,右邊為輸出流量統計。滑鼠移到 **Debug Throughput** 可以看到 **Debug** 的 Input 與 Errors 的數量,單位一樣是 EPS。
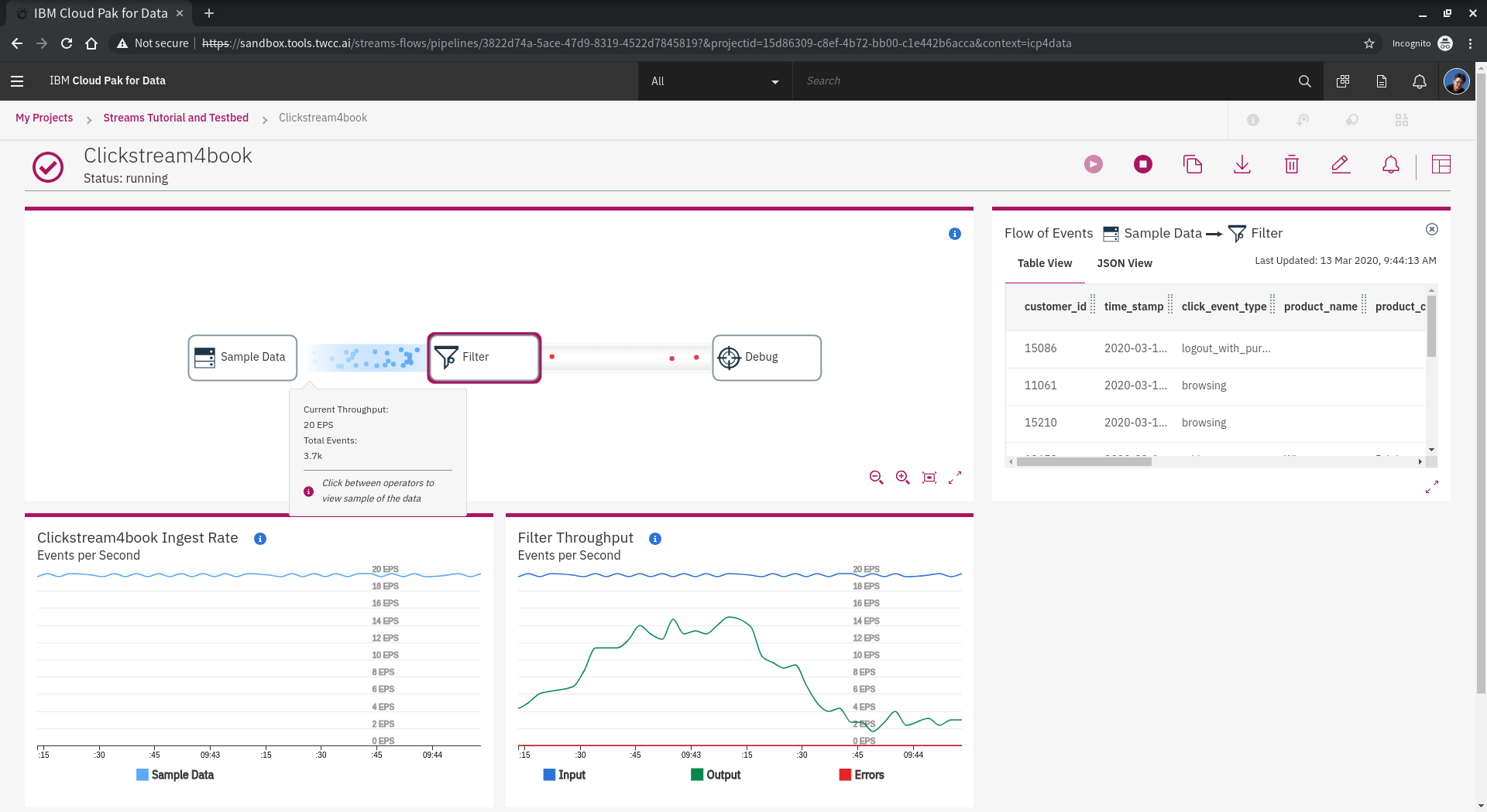
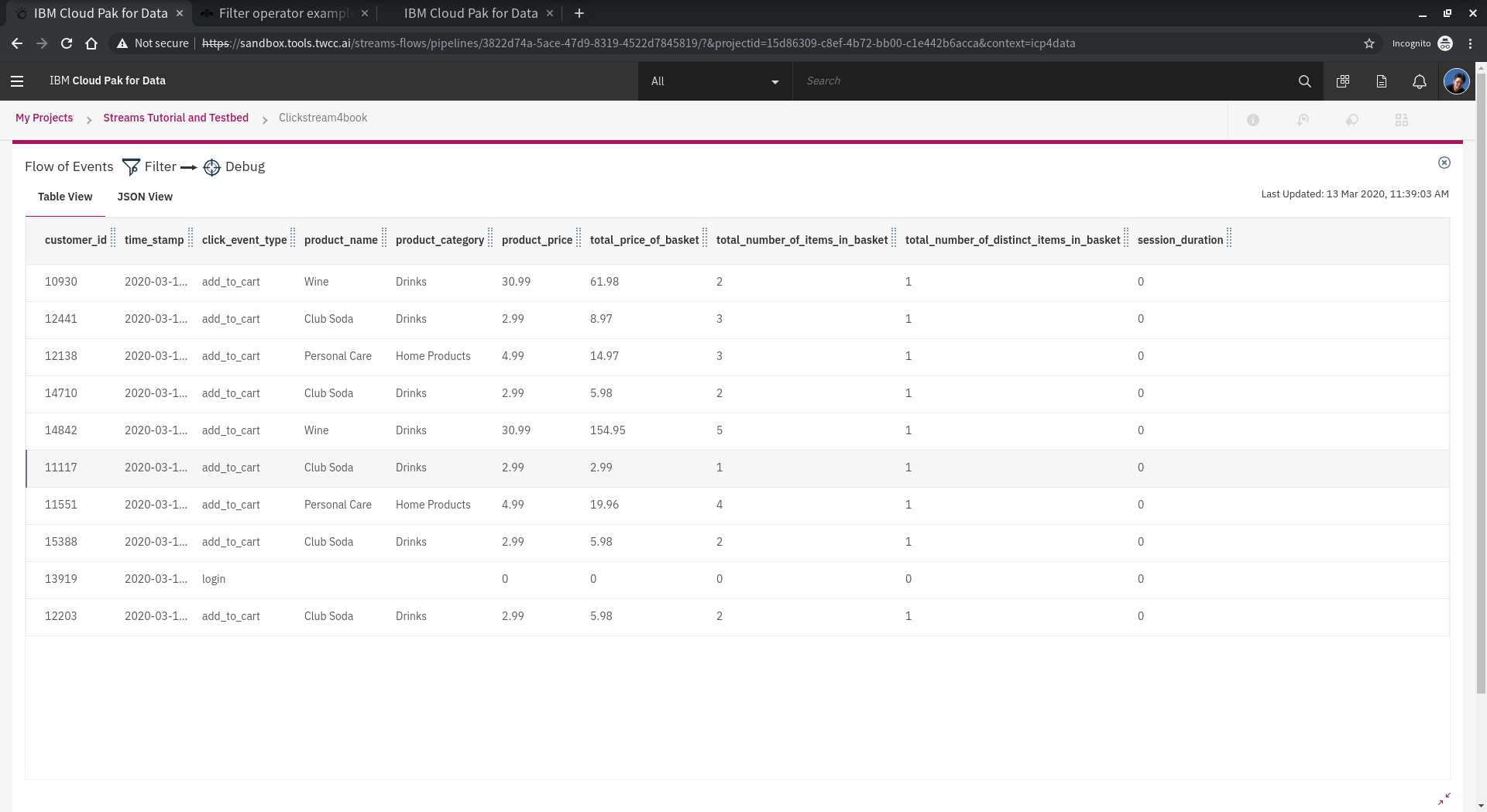
點選 Sample Data 到 Filter 的管線,可以看到目前流量與總計,並再視窗右邊可以找到 **Flow of Events** 會顯示即時資料的表格。
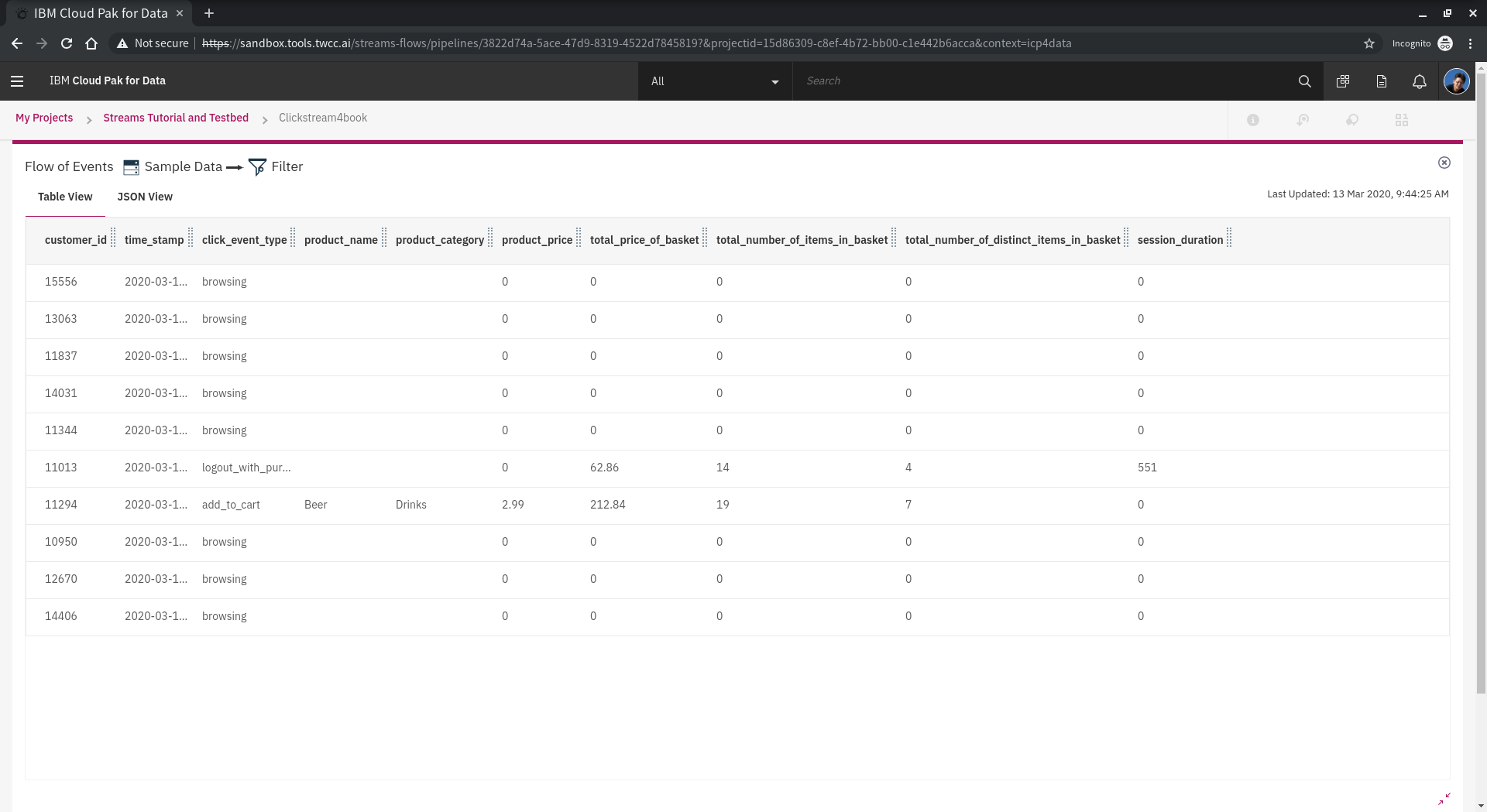
也可以在 **Flow of Events** 右下角 找到放大視窗的功能,進行資料全覽。仔細觀察資料與其變化,我們稍後會使用到幾個重點欄位進行調整,例如 click_event_type, product_type, total_price_of_basket等。
再點選 Filter 到 Debug 的管線,並且仔細觀察 **click_event_type** 之變化。
了解 streams 的應用與運作之後,可以依照我們的需求逐步練習調整 streams-flow 的功能。點選**編輯**
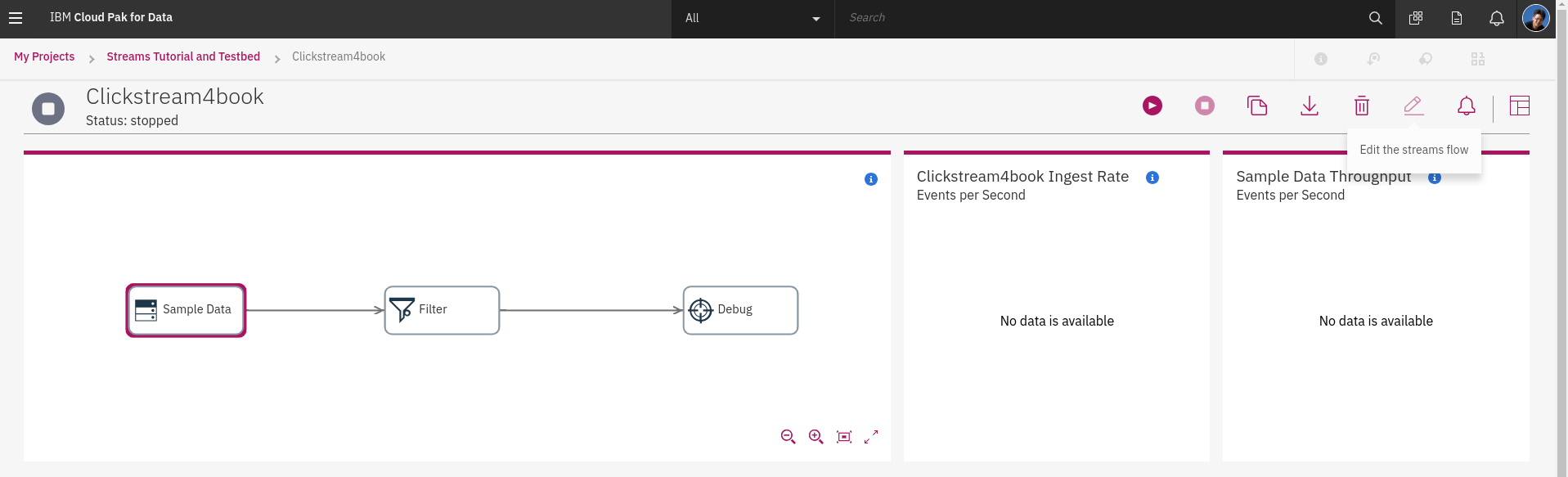
## 2.4.2 編輯 streams
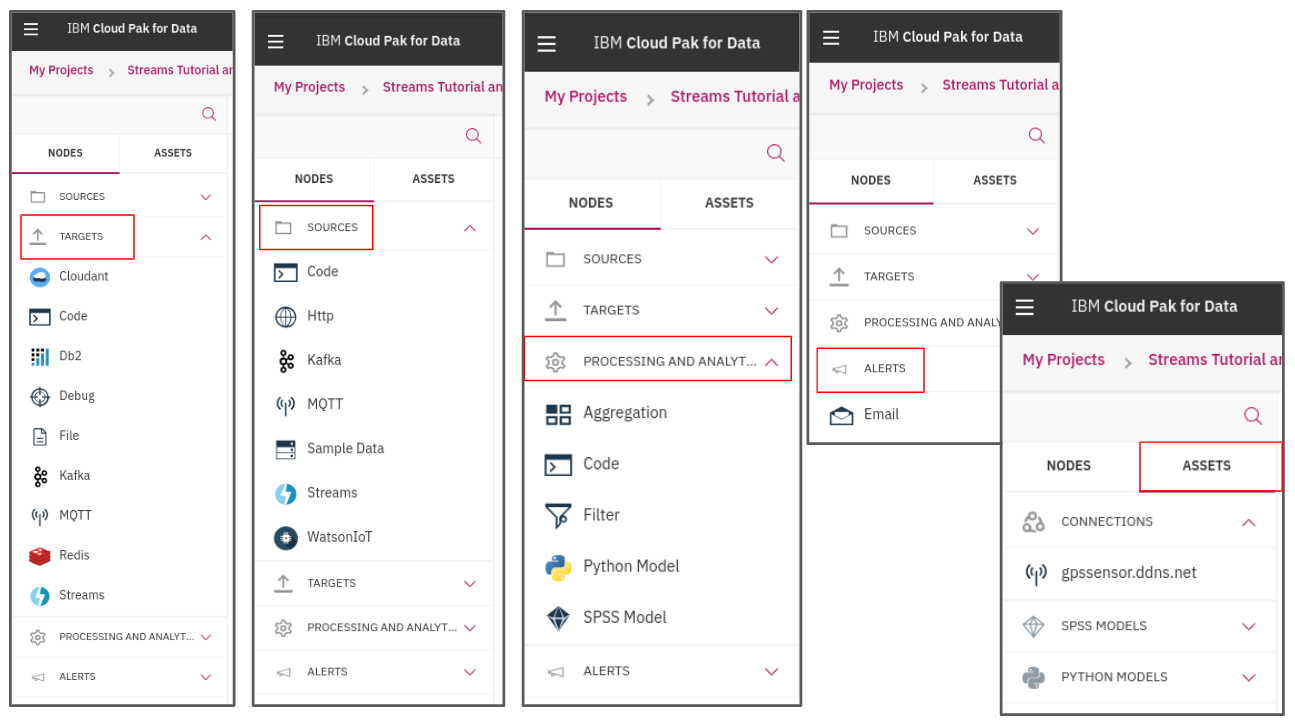
編輯畫面的左方有主要的元件可以使用,大致上功能有:
* NODES:即時資料處理元件
* source: 設定串流資料來源的處理元件集合
* target:設定串流資料目的的處理元件集合
* process:設定資料過濾、轉換的處理元件集合
* alert:設定觸發通知的處理元件
* ASSETS:連接與分析資料專案元件
<!--  -->
<!--  -->
<!--  -->
<!--  -->
<!--  -->
<!-- 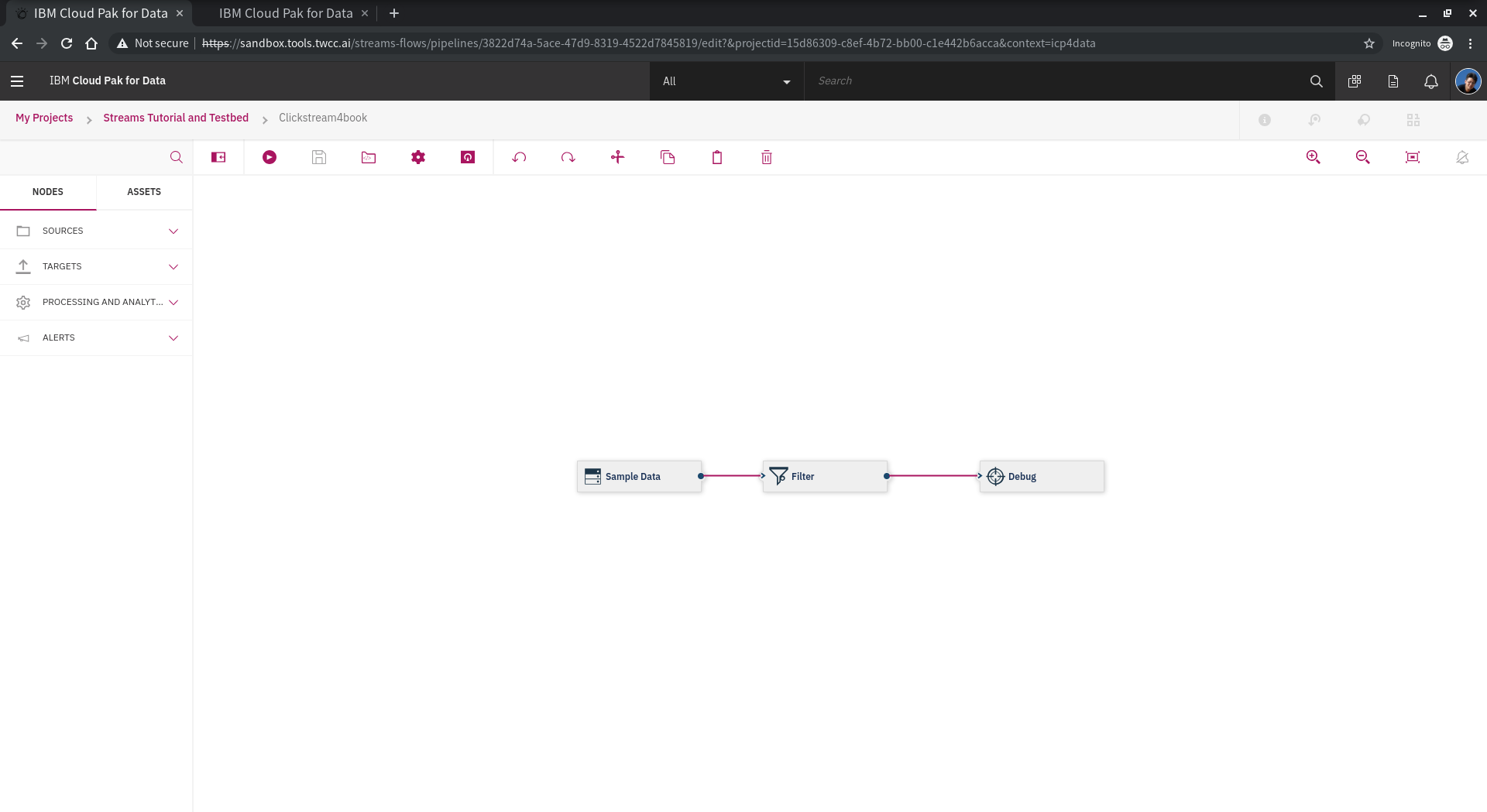 -->
點選 Sample Data ,可以看到右邊跳出的功能面板,其中可以設定不同範例資料的產生工具。本例持續以 Clickstream 進行測試。
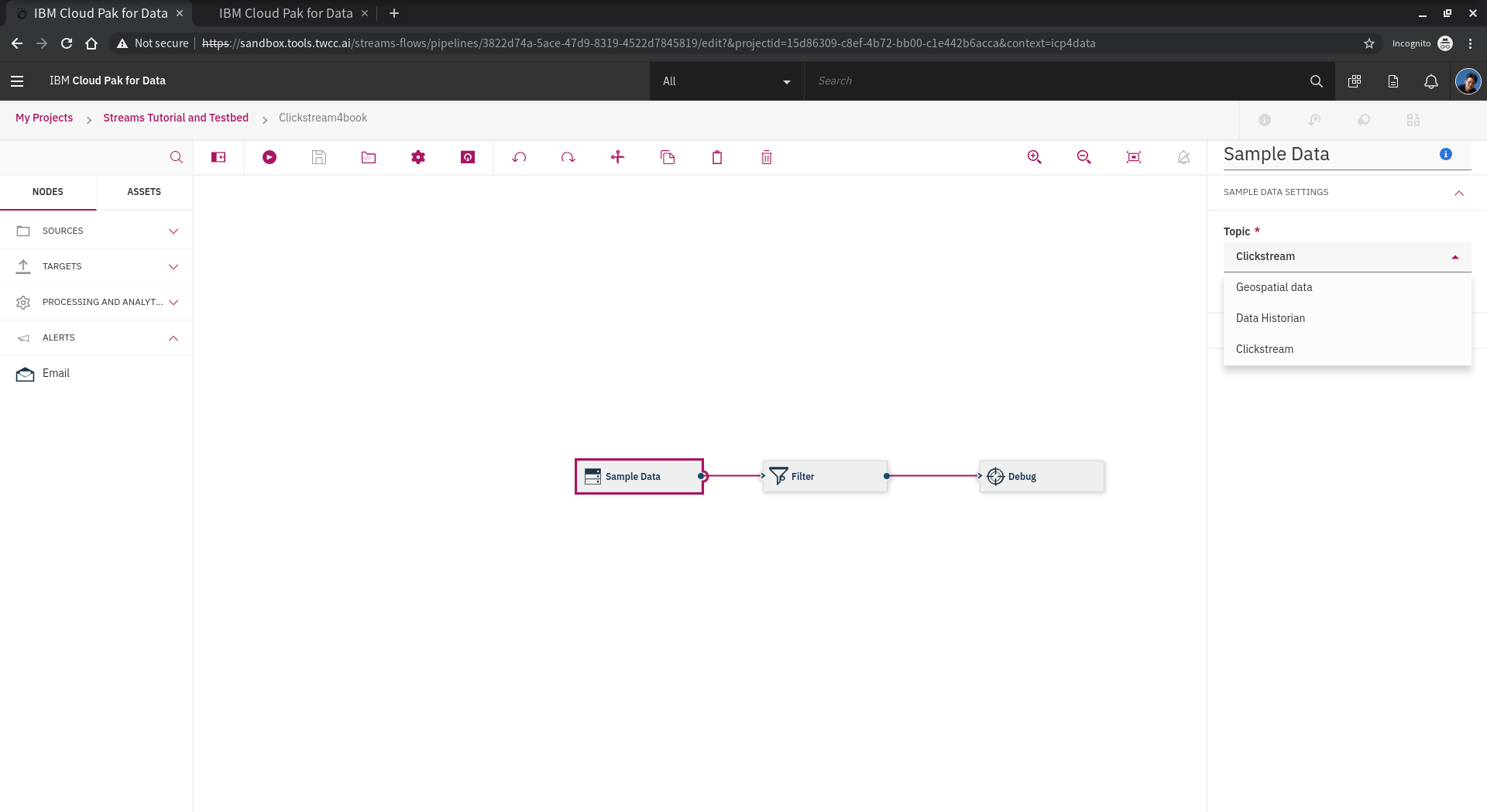
點選 Sample Data,可以看到右邊跳出的功能面板,下方可見 **Output Schema**,展開後可看到條列的欄位設定,欄位名稱、順序與型別。
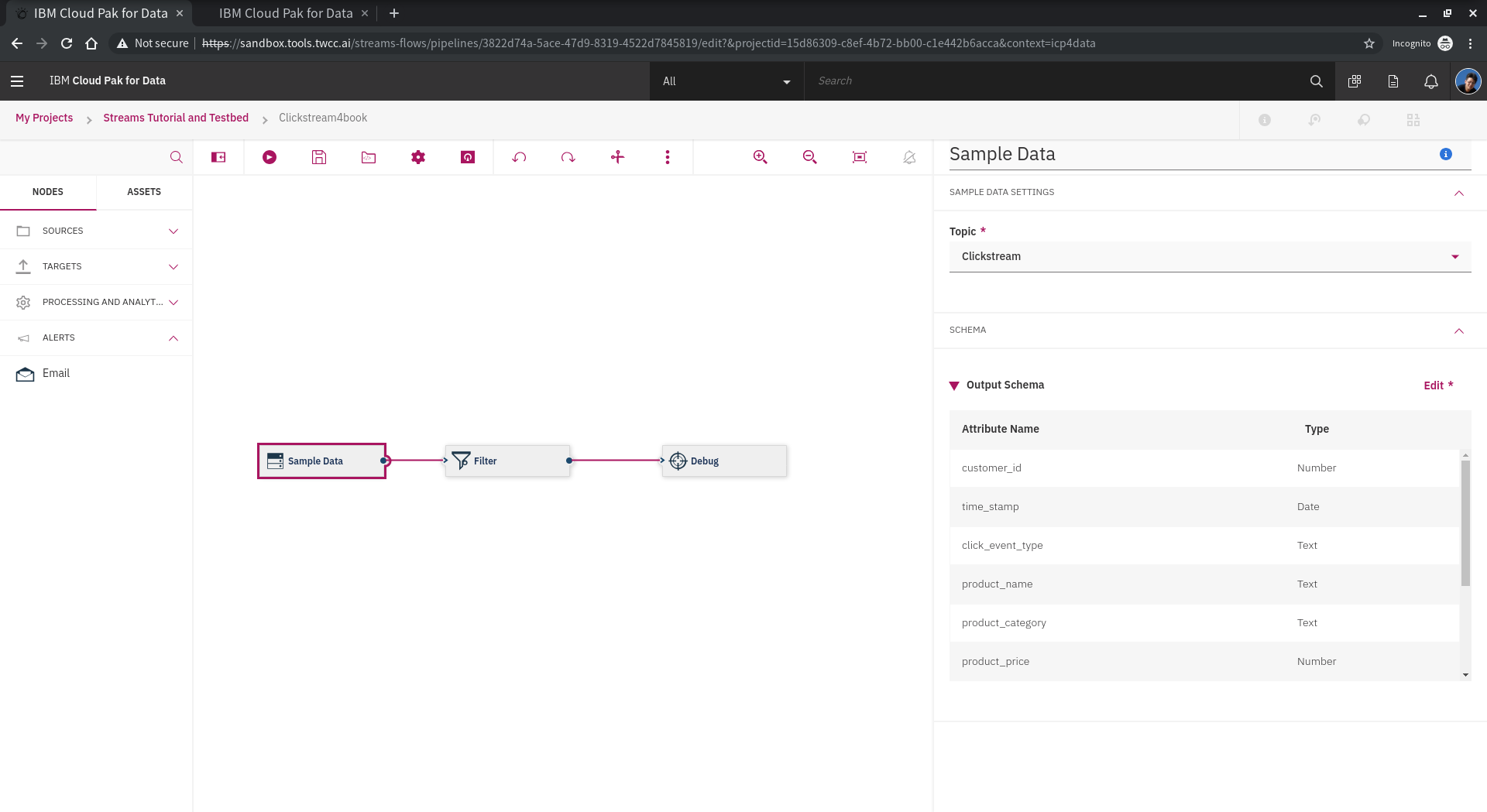
再點選 **Edit** 後,可以編輯與預覽 Schema,可以設定欄位名稱、型別、資料源路徑、排序、新增與刪除欄位。
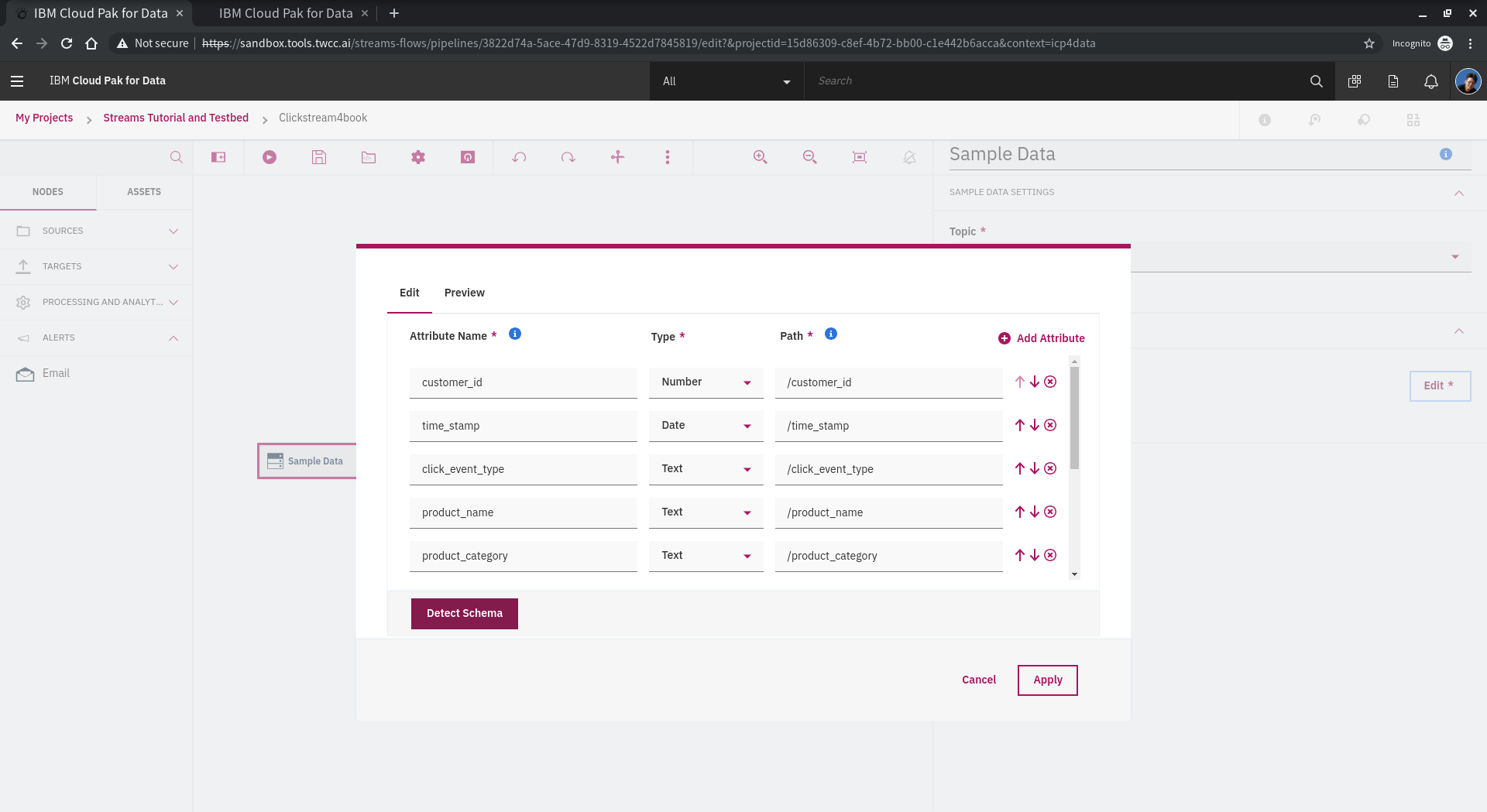
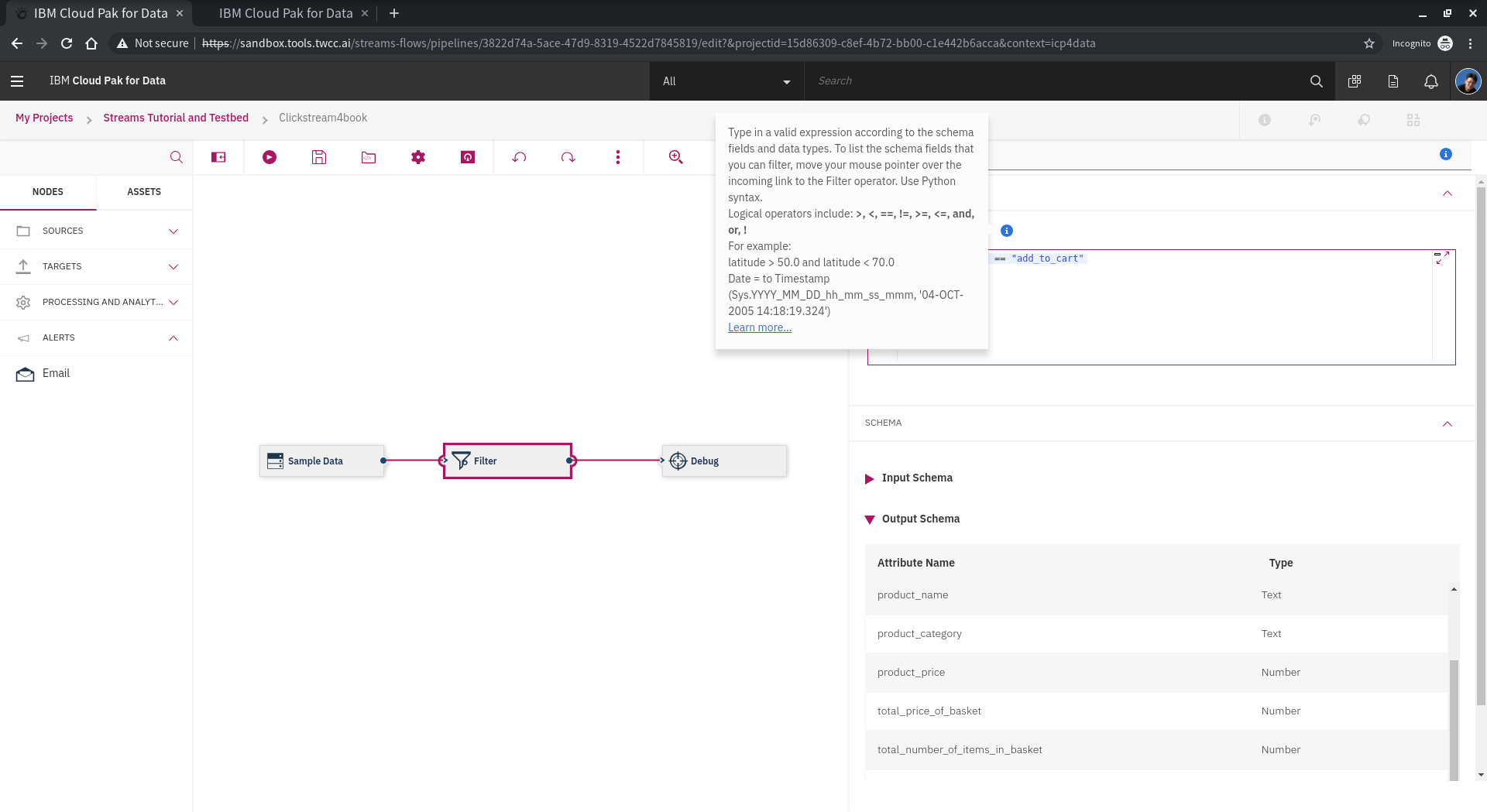
嘗試修改 **Filter** 設定,目前的設定只有
click_event_type == "add_to_cart"
嘗試加上其他條件,例如設定 增加過濾 click type 為 login 或 產品分類是食物的也過濾出來!
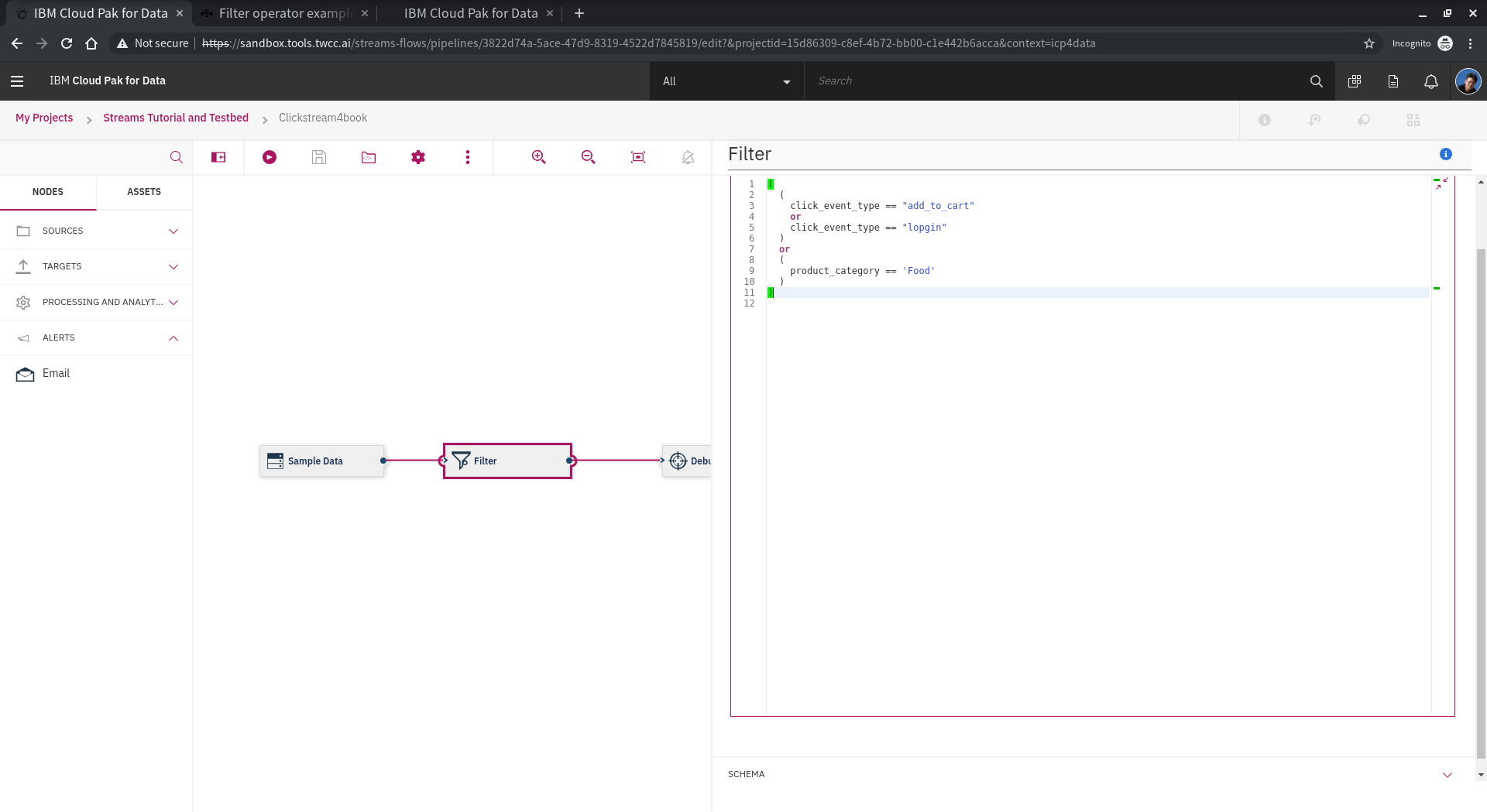
例如這樣:
(
(
click_event_type == "add_to_cart"
or
click_event_type == "login"
)
or
(
product_category == 'Food'
or
product_category == 'Wine'
)
)
設定完成之後,可以點擊畫面上方的儲存或是執行。
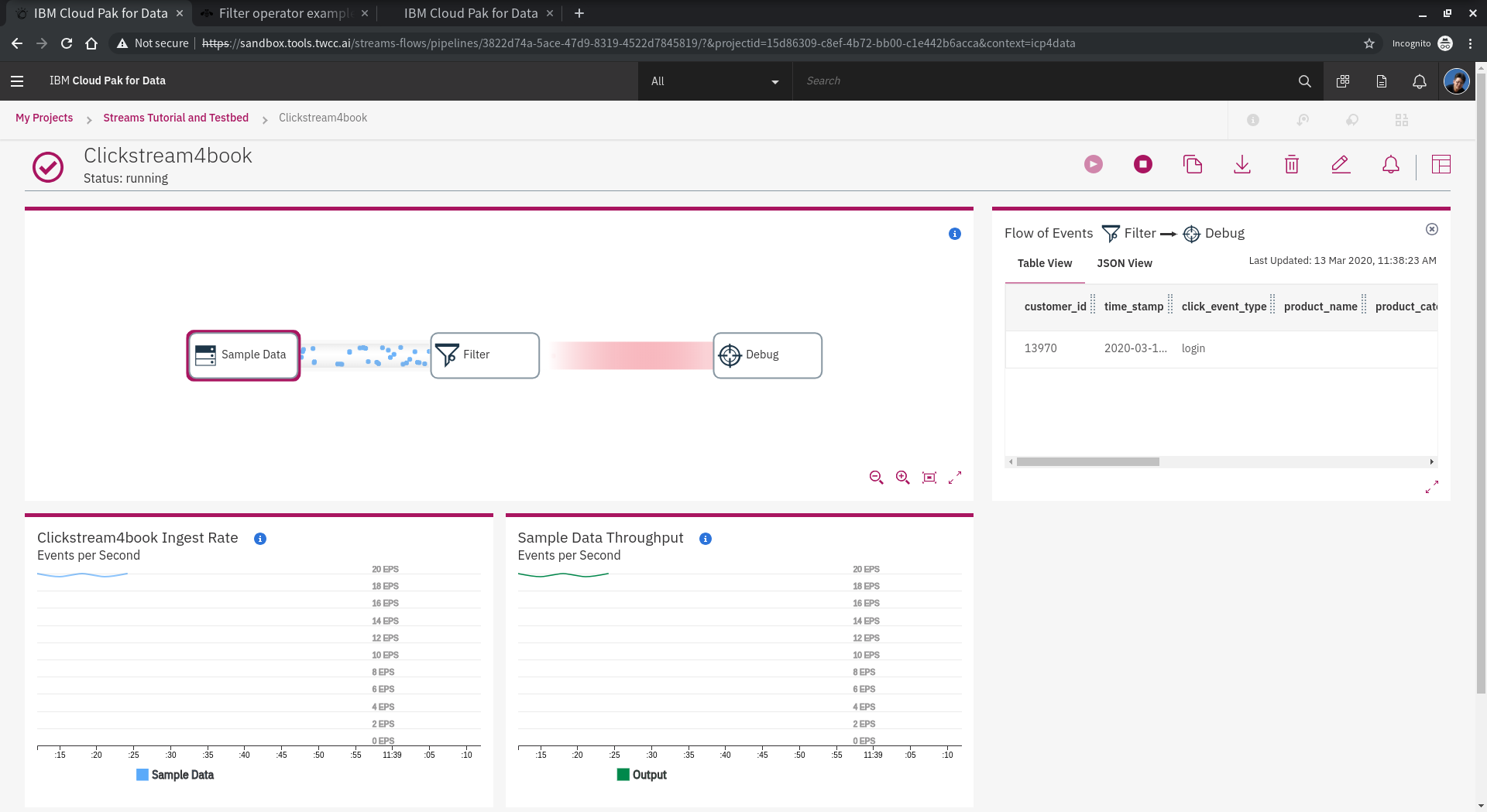
執行結果可以觀察 type 為 login or add-to-cart 都會列表出來。
除了使用UI提供的工具,我就是想要寫code,Streams flow 也提供 **code** 的功能,把 **code** 元件拉出來,完成串接,右邊的功能面板可以開始開發。其中,比較重要的是執行環境,以下分別重點說明:
* 手動安裝需要的 python module
如果有需要,使用者可以自行安裝需要的python module。點選 code,點選右邊的 Python Packages ,底下可以輸入需要的 module name,點選 Add 增加即可。
* init
在 code 裏面,主要有兩個 functions 會被使用,其中之一就是 init,整個 streams flow job 載入時會執行一次,主要進行初始化動作。
* process
在 code 裏面,主要另一個 function 會被使用,就是 produce,在 streams flow job 載入後,是 每一個 event 都會執行的function。
請參考以下示範。
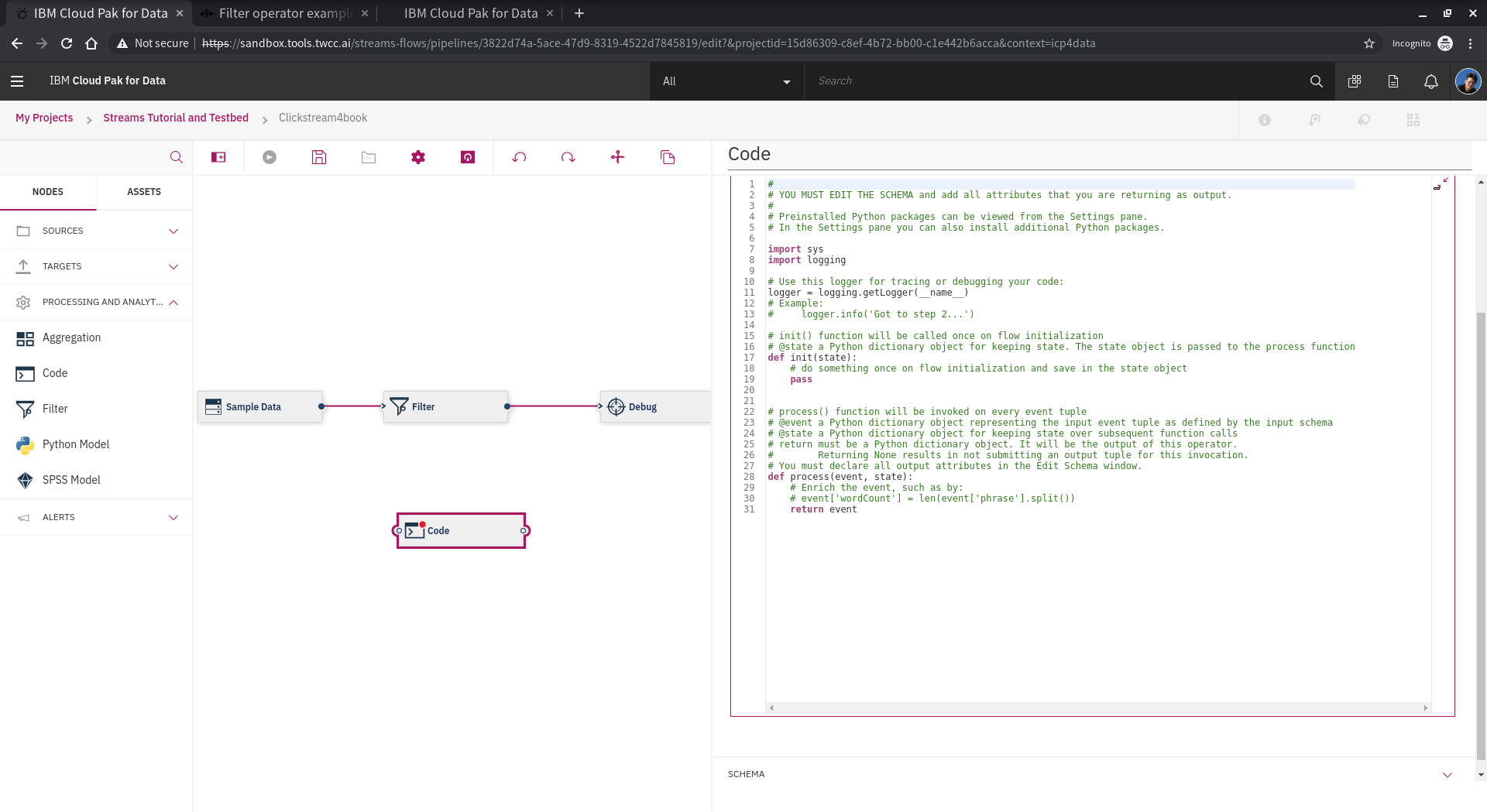
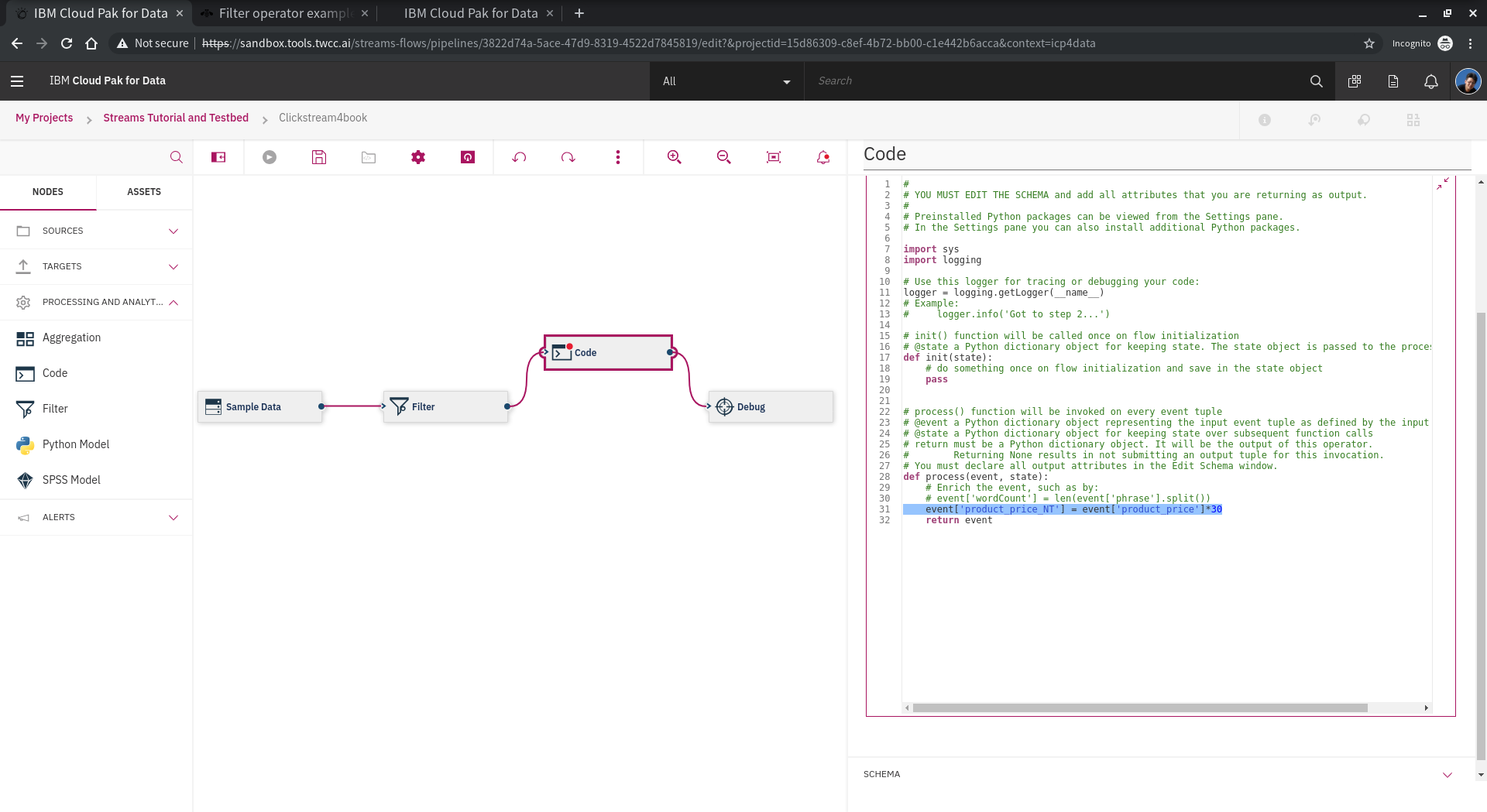
我們在這邊設計讓 price 換成 NT$,請注意 **event** 的用法。
完成code部份之後,要處理欄位,讓 streams flow 可以知道欄位的資訊,繼續串流。
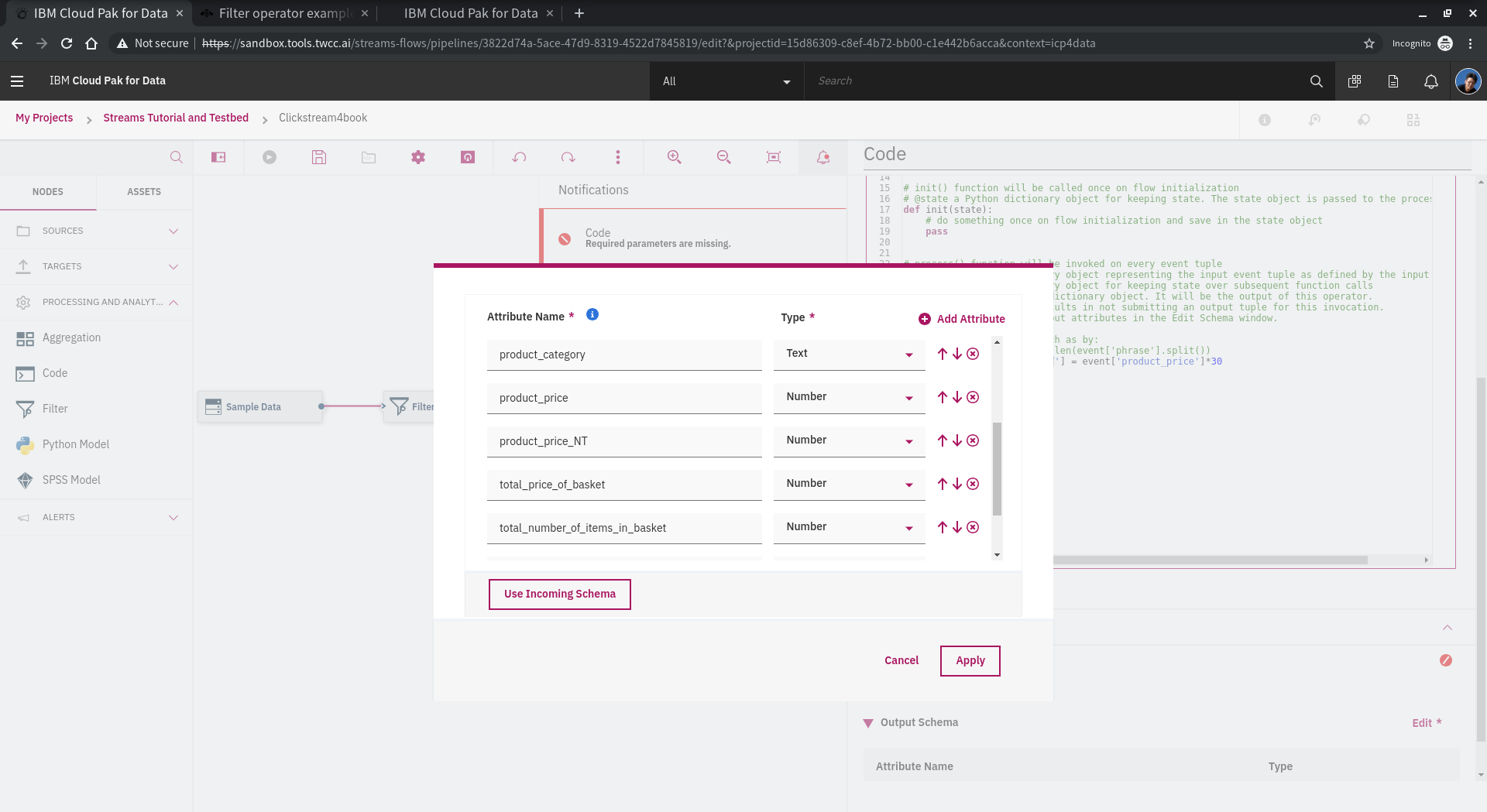
設計完成之後,可以執行測試結果!
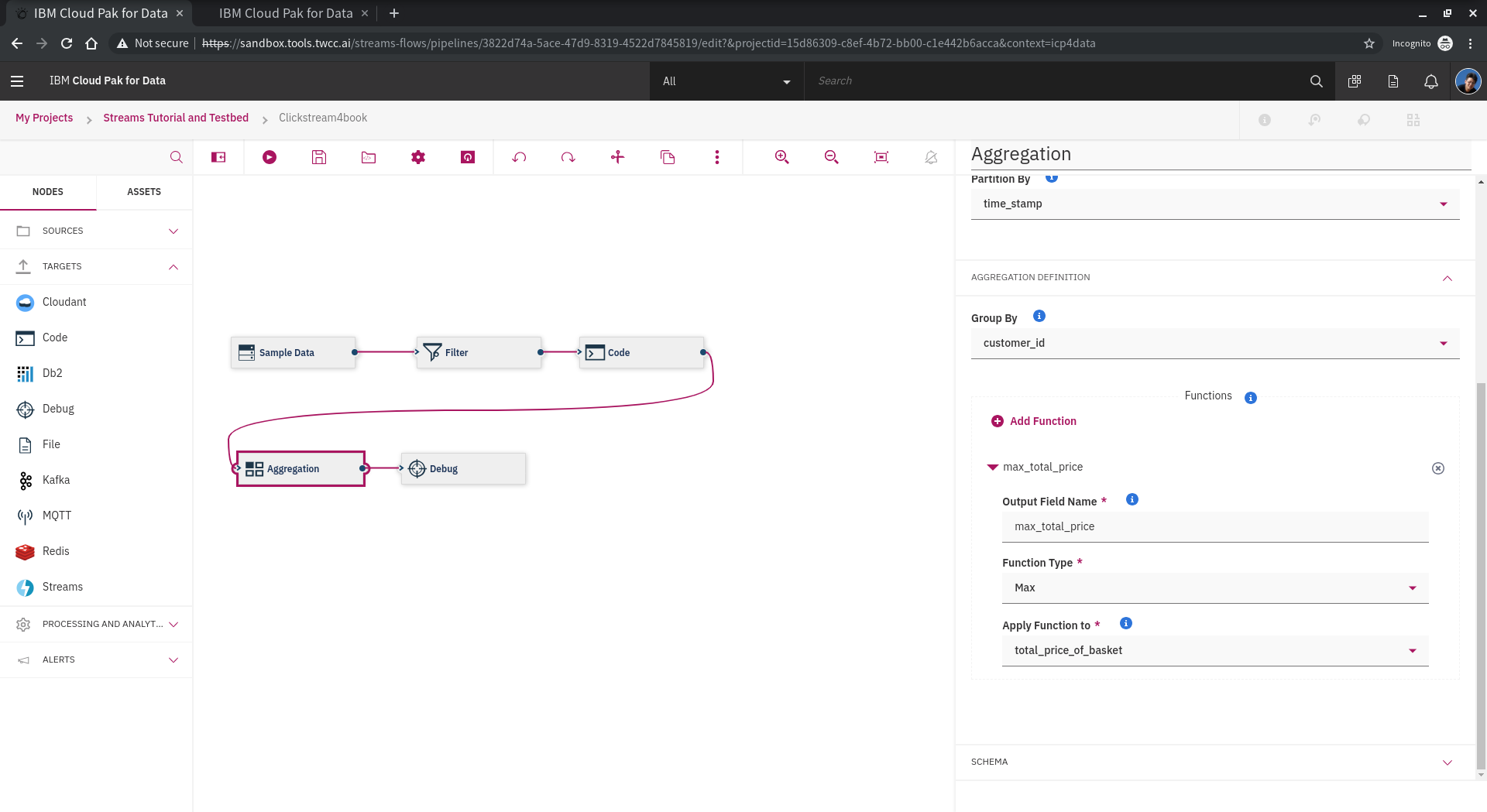
另外一個非常好的功能就是 **aggregation** 把大部份要的功能都實作了,操作簡單,可以省下很多寫code的時間。十分建議執行前先看[官方手冊](https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_current/wsj/streaming-pipelines/aggregation.html)。以下我們設計一個aggration,主要是找出時間內的最大值,並加到後續的stream之中。
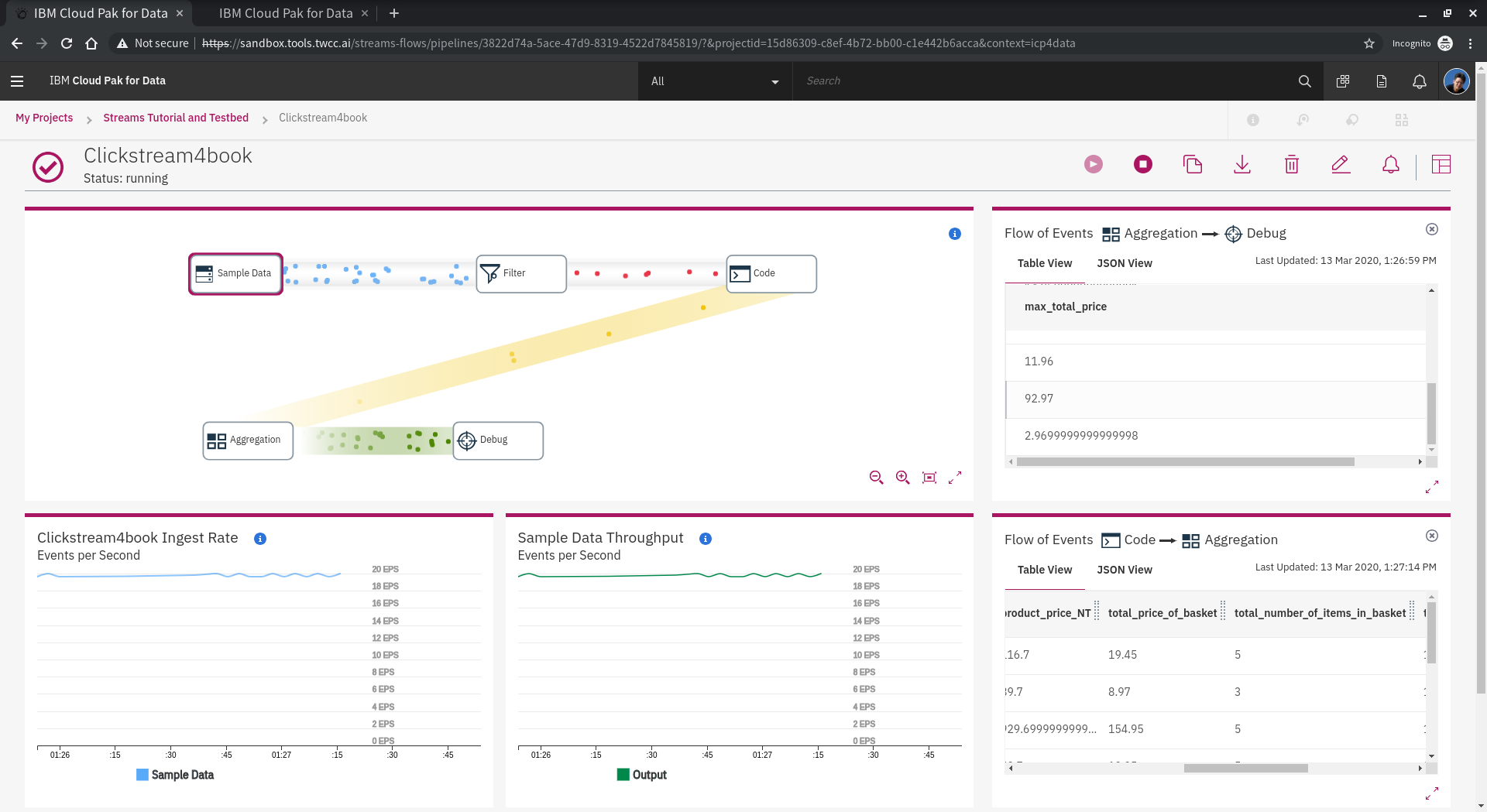
完成後,可以看到 max 的結果。
## 2.4.3 Notebook 使用 streams
以上圖多,主要是幫助大家理解 streams-flow 的功能,其實 streams 也可用 notebook 直接進行,我們期待下次進行 streams-notebook 的說明,等不及的可以先看 [範例](https://github.com/IBMStreams/sample.starter_notebooks/tree/CP4D-3.0.0.0)。
reference:
* [IBM Streaming Analytics for IBM Cloud](https://www.ibm.com/tw-zh/cloud/streaming-analytics)
* [Introductory Lab for IBM Streams 4.1 - Streamsdev](https://developer.ibm.com/streamsdev/docs/introductory-lab-for-ibm-streams-4-1/)
* [Aggregation operator examples | IBM Cloud Pak for Data](https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_current/wsj/streaming-pipelines/aggregation.html)
* Github-repository: [IBMStreams/sample.starter_notebooks at CP4D-3.0.0.0](https://github.com/IBMStreams/sample.starter_notebooks/tree/CP4D-3.0.0.0)